 Информационные технологии стремительно развиваются, если раньше виртуализация и кластера были уделом крупных организаций, то сегодня эти технологии становятся доступны даже небольшим предприятиям. Виртуализация позволяет существенно экономить на аппаратных ресурсах, но в тоже время предъявляет гораздо более серьезные требования к отказоустойчивости, поэтому еще на этапе планирования следует принять необходимые меры для ее обеспечения. Одна из таких мер - создание отказоустойчивого кластера.
Информационные технологии стремительно развиваются, если раньше виртуализация и кластера были уделом крупных организаций, то сегодня эти технологии становятся доступны даже небольшим предприятиям. Виртуализация позволяет существенно экономить на аппаратных ресурсах, но в тоже время предъявляет гораздо более серьезные требования к отказоустойчивости, поэтому еще на этапе планирования следует принять необходимые меры для ее обеспечения. Одна из таких мер - создание отказоустойчивого кластера.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Начнем с того, что термин отказоустойчивый не совсем применим к кластерным решениям, он возник в результате неверного перевода термина failover cluster. Правильный перевод - с обработкой отказа, хотя сегодня все чаще употребляется иной термин - высокой доступности (high availability), который, на наш взгляд, наиболее точно отражает суть дел.
Чтобы понять, почему кластер не является отказоустойчивым, разберем более подробно его устройство и схему работы. Сразу уточним, что кластеры применяются не только для обеспечения отказоустойчивости, также кластерные схемы применяют для балансировки нагрузки или наращивания вычислительной мощности. Однако в рамках данного материала мы будем говорить именно о высокодоступных кластерах.
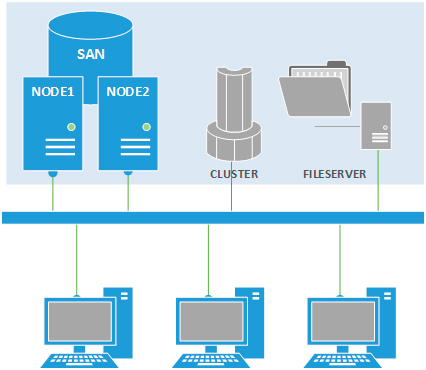
Классическая схема кластера содержит минимум два узла и общее хранилище, связанные между собой несколькими сетевыми соединениями.
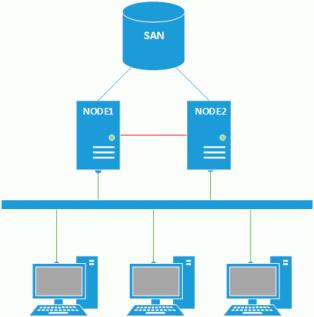 Во-первых это служебная сеть кластера для передачи сигнала "пульса" (heartbeat), по которому кластер следит за состоянием своих узлов (на схеме показана красным), сеть хранения данных (SAN, синяя), в недорогих решениях это чаще всего iSCSI через отдельную Ethernet-сеть, но это может быть также и FibreChanell или иные технологии. Для обслуживания клиентов кластер включается в существующую локальную сеть.
Во-первых это служебная сеть кластера для передачи сигнала "пульса" (heartbeat), по которому кластер следит за состоянием своих узлов (на схеме показана красным), сеть хранения данных (SAN, синяя), в недорогих решениях это чаще всего iSCSI через отдельную Ethernet-сеть, но это может быть также и FibreChanell или иные технологии. Для обслуживания клиентов кластер включается в существующую локальную сеть.
По схеме работы узлы могут работать в режиме активный-пассивный или активный-активный. В первом случае все клиентские запросы обслуживаются одним из узлов, второй узел вступает в работу только при отказе первого. Второй вариант предусматривает обработку клиентских запросов обоими узлами, при этом также можно осуществлять балансировку нагрузки и увеличивать вычислительные ресурсы, путем добавления новых узлов кластера. В случае отказа одного из узлов клиентские запросы обрабатывают оставшиеся ноды.
Важный момент - каждый клиентский запрос обслуживается только одним из узлов кластера и в случае его выхода из строя подключенные клиенты получат отказ в обслуживании, однако они могут тут-же переключиться на оставшиеся доступными узлы. Именно поэтому такая схема не является отказоустойчивой, отказ узла вызывает отказ в обслуживании, однако клиент всегда может подключиться к другому работающему узлу, что реализует как раз схему высокой доступности сервиса.
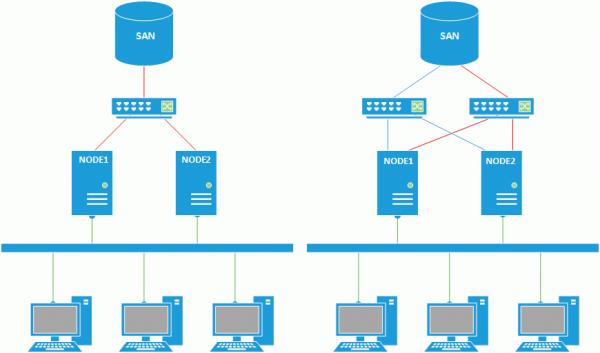
Внимательный читатель должен обратить внимание на существование в приведенной выше схеме точки отказа - хранилища. Действительно, для обеспечения высокой доступности хранилище также должно быть отказоустойчивым или высокодоступным. Это может быть реализовано как покупкой специальных аппаратных моделей, так и программно, в том числе и на базе открытого ПО.
Если в качестве хранилища используется iSCSI, то служебную сеть кластера и сеть хранения данных можно объединить. Но при этом у нас остается точка отказа - сеть, поэтому в ответственных системах следует использовать для доступа к SAN не менее двух сетей. Кроме повышения надежности данный подход позволяет повысить пропускную способность, что тоже актуально.
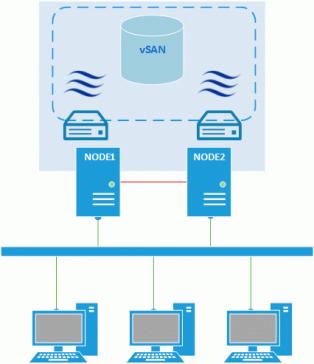
 Нельзя не упомянуть и про программные решения, позволяющие создать отказоустойчивый кластер только на двух нодах, используя в качестве SAN виртуальное хранилище. Например, StarWind Virtual SAN, который создает виртуальное iSCSI хранилище на базе локальных дисков каждого из узлов. Это позволяет снизить затраты на создание и размещение отказоустойчивого хранилища, но в тоже время повышает требование к производительности сети между узлами кластера, так как при записи на диск все изменения тут-же синхронизируются между узлами.
Нельзя не упомянуть и про программные решения, позволяющие создать отказоустойчивый кластер только на двух нодах, используя в качестве SAN виртуальное хранилище. Например, StarWind Virtual SAN, который создает виртуальное iSCSI хранилище на базе локальных дисков каждого из узлов. Это позволяет снизить затраты на создание и размещение отказоустойчивого хранилища, но в тоже время повышает требование к производительности сети между узлами кластера, так как при записи на диск все изменения тут-же синхронизируются между узлами.
После того, как вы создадите кластер, он появится в сетевом окружении как еще один хост со своим именем и IP-адресом. После чего нам потребуется развернуть на нем высокодоступные роли. Это могут быть файловые сервера, SQL или Exchange, а также иные, поддерживающие кластеризацию, приложения. Каждая отказоустойчивая роль кластера также появляется в сети в виде отдельного хоста, к которому происходит обращение клиентов. При этом клиент понятия не имеет, какой именно узел выполняет его запрос, в случае отказа, например, из-за выхода из строя одного из узлов, ему потребуется всего лишь повторить запрос к сервису.
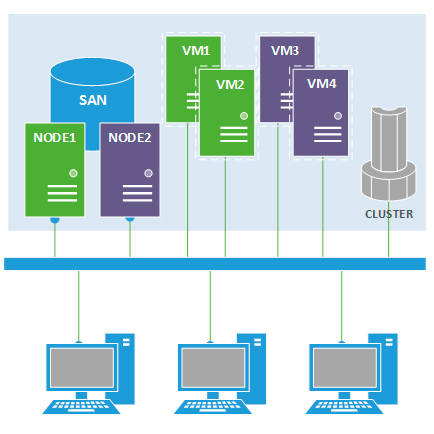
 В настоящее время кластера все чаще применяются для систем виртуализации, в этом случае виртуальные машины вручную распределяются администратором между узлами, с учетом их вычислительных ресурсов. Для каждой виртуалки указываются доступные узлы в порядке убывания приоритета. Это позволяет избежать попадания ресурсоемких виртуальных машин на слабые узлы. В случае корректного завершения работы одного из узлов кластера все работающие на нем виртуальные машины с помощью механизмов живой миграции передаются на другие узлы без остановки их работы или с постановкой на паузу.
В настоящее время кластера все чаще применяются для систем виртуализации, в этом случае виртуальные машины вручную распределяются администратором между узлами, с учетом их вычислительных ресурсов. Для каждой виртуалки указываются доступные узлы в порядке убывания приоритета. Это позволяет избежать попадания ресурсоемких виртуальных машин на слабые узлы. В случае корректного завершения работы одного из узлов кластера все работающие на нем виртуальные машины с помощью механизмов живой миграции передаются на другие узлы без остановки их работы или с постановкой на паузу.
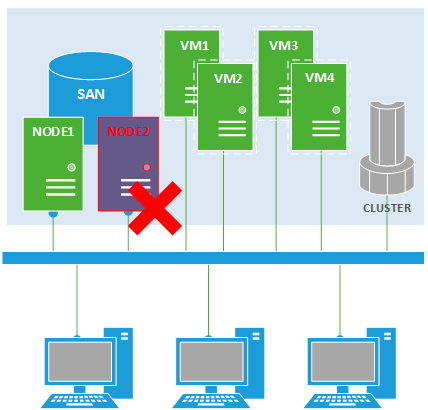
При отказе узла все выполнявшиеся на нем виртуальные машины будут перезапущены на других узлах, согласно выставленного приоритета.
Чтобы избежать черезмерной нагрузки на хранилище и сеть хранения данных, в настройках виртуальных машин можно задать задержку восстановления, так критичные виртуалки могут быть перезапущены немедленно, второстепенные - спустя некоторое время.
В наших следующих материалах мы рассмотрим практическую реализацию отказоустойчивого кластера на базе Hyper-V.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.



Последние комментарии