RAID массивы - краткий ликбез
RAID-массивы давно и прочно вошли в повседневную деятельность администраторов даже небольших предприятий. Трудно найти того, кто никогда не использовал хотя бы "зеркало", но тем не менее очень и очень многие с завидной периодичностью теряют данные или испытывают иные сложности при эксплуатации массивов. Не говоря уже о распространенных мифах, которые продолжают витать вокруг вроде бы давно избитой темы. Кроме того, современные условия вносят свои коррективы и то, чтобы было оптимальным еще несколько лет назад сегодня утратило свою актуальность или стало нежелательным к применению.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Чем является и чем не является RAID-массив
Наиболее популярен миф, что RAID предназначен для защиты данных, многие настолько верят в это, что забывают про резервное копирование. Но это не так. RAID-массив никоим образом не защищает пользовательские данные, если вы захотите их удалить, зашифровать, отформатировать - наличие или отсутствие RAID вам абсолютно не помешает. Две основных задачи RIAD-массивов - это защита дисковой подсистемы от выхода из строя одного или нескольких дисков и / или улучшение ее параметров по сравнению с одиночным диском (получение более высокой скорости обмена с дисками, большего количества IOPS и т.д.).
Здесь может возникнуть некоторая путаница, ведь сначала мы сказали, что RAID не защищает, а потом выяснилось, что все-таки защищает, но никакой путаницы нет. Основную ценность для пользователя представляют данные, причем не некоторые абстрактные нули-единицы, кластеры и блоки, а вполне "осязаемые" файлы, которые содержат необходимую нам информацию, иногда очень дорогостоящую. Мы будем в последствии называть это пользовательскими данными или просто данными.
RAID-контроллер о данных ничего не знает, он оперирует с блочными устройствами ввода-вывода. И все что поступает к нему от драйвера - это просто поток байтов, который нужно определенным образом разместить на устройствах хранения. Сам набор блочных устройств объединенных некоторым образом отдается системе в виде некоторой виртуальной сущности, которую принято называть массивом, а в терминологии контроллера - LUN, для системы это выглядит как самый обычный диск, с которым мы можем делать все что угодно: размечать, форматировать, записывать данные.
Как видим, работа RAID-контроллера закончилась на формировании LUN и предоставлении его системе, поэтому защита контроллера распространяется только на этот самый LUN - т.е. логическая структура массива, которую система видит как жесткий диск, должна уцелеть при отказе одного или нескольких дисков составляющих этот массив. Ни более, ни менее. Все что находится выше уровнем: файловая система, пользовательские данные - на это "защита" контроллера не распространяется.
Простой пример. Из "зеркала" вылетает один из дисков, со второго система отказывается грузиться, так как часть данных оказалась повреждена (скажем BAD-блок). Сразу возникает масса "претензий" к RAID, но все они беспочвенны. Главную задачу контроллер выполнил - сохранил работоспособность массива. А в том, что размещенная на нем файловая система оказалась повреждена - это вина администратора, не уделившего должного внимания системе.
Поэтому следует запомнить - RAID-массив защищает от выхода из строя одного или нескольких дисков только самого себя, точнее тот диск, который вы видите в системе, но никак ни его содержимое.
BAD-блоки и неисправимые ошибки чтения
Раз мы коснулись содержимого, то самое время разобраться, что же с ним может быть "не так". Начнем с привычного зла, BAD-блоков. Есть мнение, что если на диске появился сбойный сектор - то диск "посыпался" и его надо менять. Но это не так. Сбойные сектора могут появляться на абсолютно исправных дисках, просто в силу технологии, и ничего страшного в этом нет, обнаружив такой сектор контроллер просто заменит его в LBA-таблице блоком из резервной области и продолжит нормально работать дальше.
Дальше простая статистика, чем выше объем диска - тем больше физических секторов он содержит, тем меньше их физический размер и тем выше вероятность появления сбойных секторов. Грубо говоря, если взять произведенные по одной технологии диски объемом в 1ТБ и 4 ТБ, то у последнего вероятность появления BAD-блока в четыре раза выше.
К чему это может привести? Про ситуацию, когда администратор не контролирует SMART и у диска давно закончилась резервная область мы всерьез говорить не будем, тут и так все понятно. Это как раз тот случай, когда диск реально посыпался и его нужно менять. Большую опасность представляет иная ситуация. Согласно исследованиям, достаточно большие объемы данных составляют т.н. cold data - холодные или замороженные данные - это массивы данных доступ к которым крайне редок. Этом могут быть какие-нибудь архивы, домашние фото и видеоколлекции и т.д. и т.п., они могут месяцами и годами лежать не тронутыми никем, даже антивирусом.
Если в этой области данных возникнет сбойный сектор, то он вполне себе может остаться необнаруженным до момента реконструкции (ребилда) массива или попыток слить данные с массива с отказавшей избыточностью. В зависимости от типа массива такой сектор может привести от невозможности выполнить ребилд до полной потери массива во время его реконструкции. По факту невозможность считать данные с еще одного диска в массиве без избыточности можно рассматривать как отказ еще одного диска со всеми вытекающими.
Кроме физически поврежденных секторов на диске могут быть логические ошибки. Чаще всего они возникают, когда контроллер без резервной батарейки использует кеширование записи на диск. При неожиданной потере питания может выйти, что контроллер уже сообщил системе о завершении записи, но сам не успел физически записать данные, либо сделал это некорректно. Попав в область с холодными данными, такая ошибка тоже может жить очень долго, проявив себя в аварийной ситуации.
Ну и наконец самое интересное: неисправимые ошибки чтения - URE (Unrecoverable Read Error) или BER (Bit Error Ratio) - величина, показывающая вероятность сбоя на количество прочитанных головками диска бит. На первый взляд это очень большая величина, скажем для бытовых дисков типичное значение 10^14 (10 в 14 степени), но если перевести ее в привычные нам единицы измерения, то получим примерно следующее:
- HDD массовых серий - 10^14 - 12,5 ТБ
- HDD корпоративных серий - 10^15 - 125 ТБ
- SSD массовых серий - 10^16 - 1,25 ПБ
- SSD корпоративных серий - 10^17 - 12,5 ПБ
В данном случае в качестве единицы измерения мы использовали десятичные единицы измерения объема, т.е. те, что написаны на этикетке диска, исходя из того, что 1 КБ = 1000 Б.
Что это значит? Это значит, что для массовых дисков вероятность появления ошибки чтения стремится к единице на каждые прочитанные 12,5 ТБ, что по сегодняшним меркам не так уж и много. Если такая ошибка будет получена во время ребилда - это, как и в случае со сбойным сектором, эквивалентно отказу еще одного диска и может привести к самым печальным последствиям.
MTBF - наработка на отказ
Еще один важный параметр, который очень многими трактуется неправильно. Если мы возьмем значение наработки на отказ для современного массового диска, скажем Seagate Barracuda 2 Тб ST2000DM008, то это будет 1 млн. часов, для диска корпоративной серии Seagate Enterprise Capacity 3.5 2 Тб ST2000NM0008 - 2 млн. часов. На первый взгляд какие-то запредельные цифры и судя по ним диски никогда не должны ломаться. Однако этот показатель определяет не срок службы устройства, а среднее вермя между отказами -MTBF ( Mean time between failures ) - а в качестве времени подразумевается время работы устройства.
Если у вас есть 1000 дисков, то при MTBF в 1 млн. часов вы будете получать в среднем один отказ на 1000 часов. Т.е. большие значения оказываются не такими уж и большими. Для оценки вероятности отказа применяется иной показатель - AFR (Annual failure rate) - годовая частота отказов. Ее несложно рассчитать по формуле, где n - количество дисков:
1AFR = 1 - exp(-8750*n/MTBF)
Так для одиночного диска массовой серии годовая частота отказов составит 0,87%, а для корпоративных дисков 0,44%, вроде бы немного, но если сделать расчет для массива из 5 дисков, то мы получим уже 4,28% / 2,16%. Согласитесь, что вероятность отказа в 5% достаточно велика, чтобы сбрасывать ее со счетов. В тоже время такое знание позволяет обоснованно подходить к закупке комплектующих, теперь вы можете не просто апеллировать к тому, что вам нужны корпоративные диски, потому что они "энтерпрайз и все такое...", а грамотно обосновать свое мнение с цифрами в руках.
Но в реальной жизни не все так просто, годовая величина отказов не является статичной величиной, а подчиняется законам статистики, учитывающим совокупность реальных факторов. Не углубляясь в теорию мы приведем классическую кривую интенсивности отказов: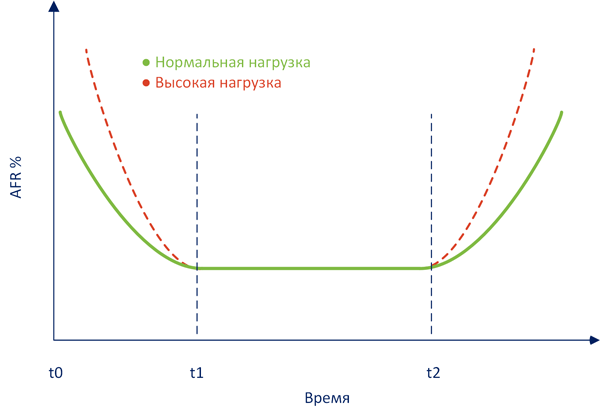
За ним следует период нормальной эксплуатации t1-t2, вероятность отказов в котором невелика и соответствует расчетным значениям (т.е. тем показателям, которые мы вычислили выше).
Правее отметки t2 на графике начинается период износовых отказов, когда оборудование начинает выходить из строя выработав свой ресурс, повышенная нагрузка будет только усугублять этот показатель. Также обратите внимание, что функция износа изменяется не линейно, по отношении ко времени, а по логарифмической функции. Т.е. в периоде износа отказы будут увеличиваться постепенно, а не сразу, но, с какого-то момента стремительно.
К чему это может привести? Скажем, если вы эксплуатируете массив, находящийся в периоде износовых отказов и у него выходит из строя один из дисков, то повышенная нагрузка во время ребилда способна привести к новым отказам, что чревато полной потерей массива и данных.
Для жестких дисков и SSD, согласно имеющейся статистики, период приработки где-то равен 3-6 месяцам. А период износовых отказов следует начинать отсчитывать с момента окончания срока гарантии производителя. Для большинства дисков это два года. Это хорошо укладывается в ту же статистику, которая фиксирует увеличение количества отказов на 3-4 году эксплуатации.
Мы не будем сейчас делать выводы и давать советы, приведенных нами теоретических данных вполне достаточно, чтобы каждый мог самостоятельно оценить собственные риски.
Немного терминологии
Прежде чем двигаться дальше - следует определиться с используемыми терминами, тем более что с ними не все так однозначно. Путаницу вносят сами производители, используя различные термины для обозначения одних и тех же вещей, а перевод на русский часто добавляет неопределенности. Мы не претендуем на истину в последней инстанции, но в дальнейшем будем придерживаться описанной ниже системы.
Весь входящий поток данных разбивается контроллером на блоки определенного размера, которые последовательно записываются на диски массива. Каждый такой блок является минимальной единицей данных, с которой оперирует RAID-контроллер. На схеме ниже мы схематично представили массив из трех дисков (RAID 5).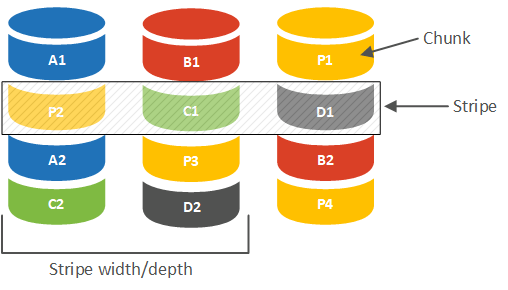
Группа блоков (чанков) расположенная по одинаковым адресам на всех дисках массива обозначается в русскоязычных терминах как лента или полоса. В англоязычной снова используется Stripe, а также**"страйп"** в переводах, что в ряде случаев способно внести путаницу, поэтому при трактовании термина всегда следует учитывать контекст его употребления.
Каждая полоса содержит либо набор данных, либо данные и их контрольные суммы, которые вычисляются на основе данных каждой такой полосы. Глубиной или шириной полосы (Stripe width/depth) называется объем данных, содержащийся в каждой полосе.
Так если размер чанка равен 64 КБ (типовое значение для многих контроллеров), то вычислить ширину полосы мы можем, умножив это значение на количество дисков с данными в массиве. Для RAID 5 из трех дисков - это два, поэтому ширина полосы будет 128 КБ, для RAID 10 из четырех дисков - это четыре и ширина полосы будет 256 КБ.
RAID 0
Перейдем, наконец от теории, к разбору конкретных реализаций RAID. Из всех вариантов RAID 0 - единственный тип массива, который не содержит избыточности, также его еще называют чередующимся массивом или страйпом (Stripe).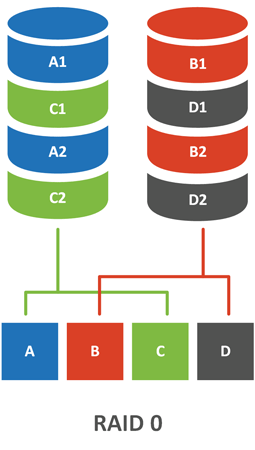
Несложно заменить, что отказ даже одного диска будет для массива фатальным, поэтому в чистом виде он практически не используется, разве что в тех случаях, когда на первый взгляд выходит быстродействие, при низких требованиях к сохранности данных. Например, рабочие станции, которые размещают на таких массивах только рабочий набор данных, который обрабатывается в текущий момент.
RAID 1
Один из самых популярных видов массивов, знакомый, пожалуй, каждому. RAID 1, он же зеркало (Mirror), состоит обычно из двух дисков, данные на которых дублируют друг друга.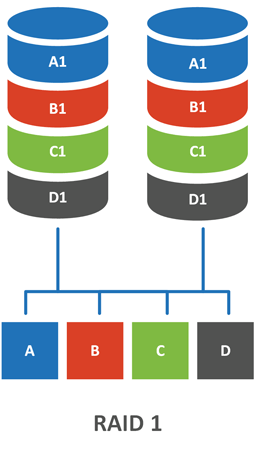
Но за это приходится платить большими потерями емкости - емкость массива равна емкости одного диска, поэтому зеркала с более чем двумя дисками на практике не используют. Также это негативно сказывается на быстродействии. Вспомним, что еще одной причиной объединения дисков в массивы является увеличение быстродействия, при этом важна не линейная скорость записи / чтения, а количество операций ввода вывода в секунду - IOPS - которые может предоставить диск.
В первом приближении общее количество IOPS массива - это суммарное количество IOPS его дисков, но на практике оно будет меньше за счет накладных расходов в самом массиве. В RAID 1 для выполнения одной операции записи массив производит две записи данных, по одной на каждый диск. Этот параметр называется RAID-пенальти и показывает сколько операций ввода вывода делает массив для обеспечения одной операции записи. Операции чтения не подвержены пенальти.
Для RAID 1 пенальти равно двум. Поэтому его производительность на запись не отличается от производительности одиночного жесткого диска. На чтение, теоретически, можно достичь двойной производительности за счет одновременного чтения с разных дисков, но на практике такая функция в контроллерах не реализуется. Поэтому чтение с зеркала также не отличается по производительности от одиночного диска.
Как видим, RAID 0 предоставляет нам высокую производительность при отсутствии надежности, а RAID 1 - высокую надежность без увеличения производительности. Поэтому существуют комбинированные уровни RAID, сочетающие достоинства нескольких типов массивов.
RAID 01 (0+1)
Этот тип массива часто путают с RAID 10, но это неверно, первым числом в наименовании массива всегда указывается вложенный массив, а вторым - внешний. Таким образом RAID 01 - зеркало из страйпов, а RAID 10 - страйп из зеркал. Какая разница? А вот сейчас и посмотрим.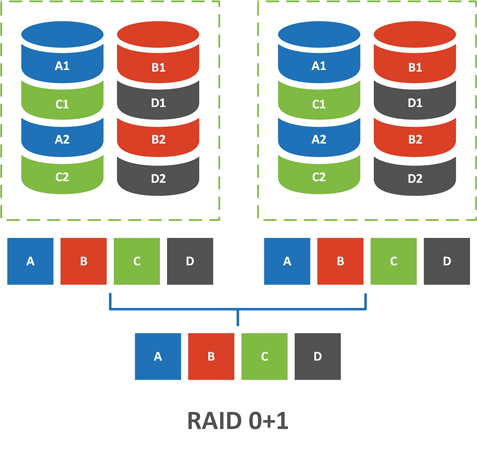
Так как внешним массивом является RAID 1 - зеркало, то на оба вложенных чередующихся массива подается одинаковый набор данных, который распределяется без избыточности по дискам массива. В итоге получаем два одинаковых RAID 0 массива, которые собраны в зеркало.
Что случится при отказе одного диска? Ничего страшного, массив выдерживает такой отказ. А если выйдут из строя два? В этом случае возможны варианты: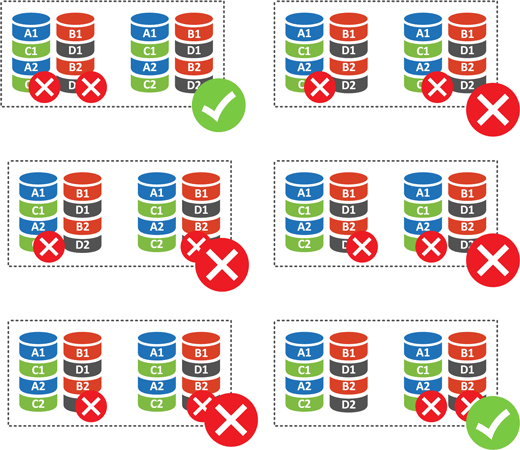
Для массива из четырех дисков (а это минимальное количество для этого уровня RAID) у нас есть шесть вариантов отказа двух дисков. Исходя из того, что отказ из любого диска RAID 0 является для него фатальным, то получаем 4 отказа из 6 или 66,67%. Т.е. при потере двух дисков вы потеряете свои данные с вероятностью 66,67%, что довольно-таки много.
RAID 10
"Десятка" также собирается минимум из 4 дисков, но внутренняя структуре ее зеркально отличается от 0+1: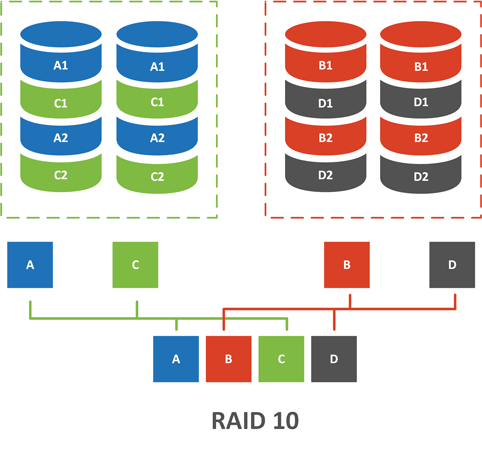
Массив верхнего уровня RAID 0 - делит входящие данные и распределяет их между низлежащими массивами RAID 1. В итоге получаем чередующийся массив из нескольких зеркал. В чем тут принципиальная разница с предыдущим массивом? А вот в чем, снова рассмотрим ситуацию отказа сразу двух дисков: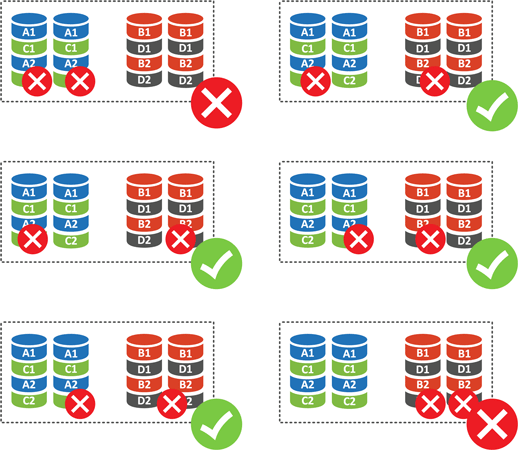
В отличие от страйпа, для отказа зеркала нужен выход из строя обоих диском массива и только эта ситуация приведет к полному отказу RAID 10, из 6 вариантов это произойдет только в двух случаях, т.е. вероятность потери данных при отказе двух дисков в RAID 10 равна 33,33%. А теперь сравните это с 66,77% у RAID 0+1, поэтому в настоящее время применяется исключительно RAID 10, так как при одинаковых показателях производительности обеспечивает гораздо более высокую надежность.
Пенальти RAID 10, также, как и RAID 1 равно двум, но за счет наличия четырех дисков он обеспечивает скоростные показатели аналогичные RAID 0 при надежности сопоставимой с RAID 1, емкость массива равна емкости половины его дисков.
На сегодня RAID 10 - наиболее производительный RAID-массив с высокой надежностью, его единственный и довольно существенный недостаток - высокие накладные расходы - 50% (половина дисков используется для создания избыточности).
RAID 5
Существует распространенное заблуждение, что RAID 5 (и RAID 6) - это более "крутые" уровни RAID, правда редко кто при этом может пояснить чем они "круче", но миф продолжает жить и очень часто администраторы выбирают уровень RAID исходя из таких вот заблуждений, а не реальных показателей.
Устройство RAID 5 более сложно, чем у "младших" уровней RAID и здесь появляется понятие контрольной суммы, на же Рarity, четность. В основу алгоритма положена логическая функция XOR (исключающее ИЛИ), так для трех переменных будет справедливо равенство:
1a XOR b XOR c = p
Где p - контрольная сумма или четность. При этом мы всегда можем вычислить любую из переменных зная четность и остальные значения, т.е.:
1a = p XOR b XOR c
2b = a XOR p XOR c
3c = a XOR b XOR p
Данные формулы остаются справедливы для любого количества переменных, позволяя обходится единственным значением четности. Таким образом минимальное количество дисков в RAID 5 будет равно трем: два диска для данных и один диск для четности. Раньше существовали реализации RAID 3 и 4, которые использовали для хранения блоков четности отдельный диск, что приводило к высокой нагрузке на него, в RAID 5 поступили иначе.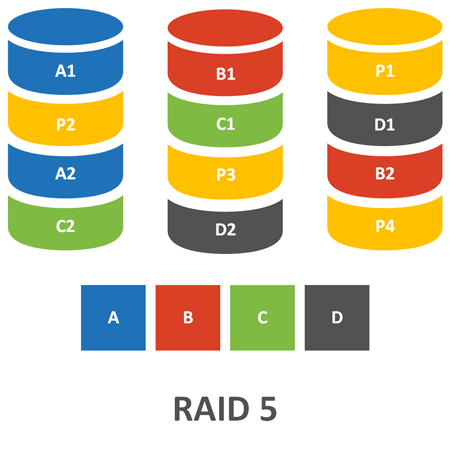
Здесь данные точно также разбиваются на блоки и распределяются по дискам, как в RAID 0, но появляется еще и понятие полосы, для каждой полосы данных вычисляется контрольная сумма и записывается в той же полосе на отдельном диске, т.е. один из дисков полосы выполняет роль диска для хранения четности. В следующей полосе происходит чередование дисков, теперь два других диска будут хранить данные, а третий четность. Таким образом достигается равномерное использование всех дисков, что снижает нагрузку на диски и повышает производительность массива в целом.
Основным стимулом создания RAID 5 было более оптимальное использование дисков в массиве, так в массиве из 3 дисков накладные расходы RAID 5 составят 33%, из 4 дисков - 25 %, из 6 дисков - 16%. Но при этом вырастает пенальти, в RAID 5 на одну операцию записи приходятся операции: чтение данных, чтение четности, запись новых данных, запись четности. Таким образом пенальти для RAID 5 составляет четыре.
Это означает, что производительность на запись массивов из небольшого числа дисков (менее 5) будет ниже, чем у одиночного диска, но производительность чтения будет сравнима с RAID 0. При этом массив допускает отказ любого одного диска.
В этом месте мы подходим к развенчанию одного из мифов, что RAID 5 "круче", нет, он не "круче", а по производительности даже уступает тому же RAID 10 (а иногда даже и зеркалу). Но по соотношению производительности, накладных расходов и надежности данный уровень RAID представлял наиболее разумный компромисс, что и обеспечило его популярность.
Внимательный читатель заметит, что в прошлом абзаце мы высказались о преимуществах RAID 5 в прошедшем времени, действительно это так, но, чтобы понять почему, следует поговорить о недостатках, которые наиболее ярко проявляются при выходе из строя одного из дисков.
В отличие от RAID 1 / 10 при отказе диска RAID 5 не будет содержать полной копии данных, только их часть плюс контрольные суммы. Это означает что у нас появится пенальти на чтение - для чтения недостающего фрагмента данных нам потребуется полностью считать полосу и провести ряд вычислений для восстановления отсутствующих значений. Это резко снижает производительность массива и увеличивает нагрузку на него, что может привести к выходу из строя оставшихся дисков.
При отказе одного диска массив переходит в режим деградации, при этом по его надежность начинает соответствовать RAID 0, т.е. отказ еще одного диска, BAD-блок или ошибка URE могут стать для него фатальными. При замене неисправного диска массив переходит в режим реконструкции (ребилда), который сопряжен с высокой нагрузкой на оборудование, так как для восстановления контроллер должен прочитать весь объем данных массива. Любой сбой в процессе ребилда также может привести к полному разрушению массива.
А теперь вспомним значение URE для современных массовых дисков - 10^14, что это значит в нашем случае? А то, что собрав RAID 5 из четырех дисков на 4 ТБ (с объемом данных 12 ТБ) вы с вероятностью очень близкой к 100% получите невосстановимую ошибку чтения при ребилде и потеряете массив полностью.
Но это не значит, что RAID 5 изначально имел столь критические недостатки. Вернемся на 10 лет назад, основной объем ходовых моделей дисков тогда составлял 250-500 ГБ, URE для популярной тогда серии Barracuda 7200.10 был теми же 10^14, а MTBF был немного ниже - 700 тыс. часов.
Допустим мы собрали тогда массив из 4 дисков по 750 ГБ (топовые диски на тот момент), объем данных такого массива составит 2,25 ТБ, вероятность получить URE будет в районе 18%. В общем и целом - немного, большинство успешно реконструировало массив, а голоса тех, кому не повезло, тонули в общем хоре тех, у кого все было хорошо.
Но сегодня RAID 5 в принципе неприменим с массовыми сериями дисков, и с определенными оглядками применим на корпоративных сериях. Не смотря на более высокое значение URE последних, не будем забывать о возможных сбойных областях в зоне холодных данных, а чем больше объем дисков, тем больше секторов, тем больше вероятность сбоя в одном из них.
Также это хорошая иллюстрация пагубности мифов, так как собрав сегодня "крутой" массив RAID 5 вы с очень большой вероятностью просто угробите все свои данные при отказе одного из дисков.
RAID 5E
Как мы уже успели выяснить, ситуация с отказом одного из дисков является для RAID 5 критической - массив переходит в режим деградации с серьезным падением производительности и существенным ростом нагрузки на диски, а его надежность падает до уровня RAID 0 и любая ошибка способна полностью разрушить массив с полной потерей данных. Поэтому чем быстрее мы заменим сбойный диск - тем скорее выведем массив из зоны риска.
Первоначально этот вопрос решался, да и решается до сих пор, выделением диска горячей замены. Такой диск может быть выделенным, т.е. привязанным к указанному массиву, или разделяемым, тогда в случае отказа он будет использован одним из отказавших массивов. Но у этого подхода есть серьезный недостаток - фактически мы никак не используем резервный диск, а так как отказы происходят не каждый день, то его ресурс просто тратится впустую.
RAID 5E предлагает иной подход, пространство резервного диска разделяется между остальными дисками и остается неразмеченным в конце каждого диска массива.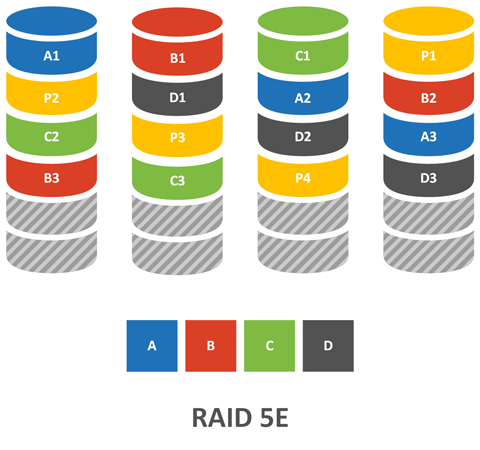
Такой подход связан с некоторыми ограничениями, а именно - один раздел на один массив. Из плюсов - более высокая производительность за счет использования дополнительного диска. Что происходит при отказе? Массив автоматически начинает реконструкцию размещая данные в неразмеченной области (производит сжатие), после чего массив фактически превращается в простой RAID 5 и способен выдержать отказ еще одного диска (но не во время перестроения).
При замене неисправного диска массив переносит данные из резервной области на новый диск и снова начинает работать как RAID 5E (производит развертывание), при этом операция развертывания не сопряжена с дополнительными рисками, отказ диска или ошибка в данной ситуации не будут фатальными.
RAID 5EE
Дальнейшее развитие RAID 5E, в котором отказались из за размещения резервной области в конце диска (самая медленная его часть), а разбили ее на блоки и также как и блоки четности начали чередовать между дисками. Основное преимущество такого подхода - это более быстрый процесс реконструкции, а так как в этом состоянии массив особо уязвим, то уменьшение времени ребилда - это повышение надежности всего массива.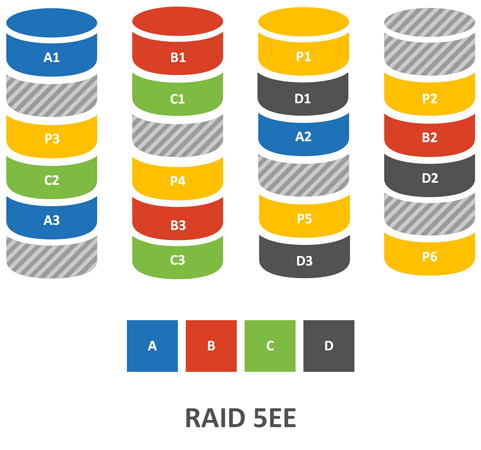
Кроме того, такой подход позволяет выровнять нагрузку по дискам, что должно положительно сказываться на надежности. Ограничения остались те же - один раздел на один массив.
Также ни RAID 5E, ни RAID 5EE не лишились недостатка простого RAID 5 - на современных объемах массивов вероятность успешного ребилда такого массива очень невелика.
RAID 6
В отличие от RAID 5 этот массив использует две контрольные суммы и два диска четности, поэтому для него понадобятся 4 диска, при этом допускается выход из строя двух из них. Также, как и у RAID 5 алгоритм позволяет использовать всего две контрольные суммы вне зависимости от ширины полосы и общий объем массива всегда будет равен объему всех дисков за вычетом двух. При отказе одного диска RAID 6 выдерживает отказ еще одного, либо ошибку чтения без фатальных последствий.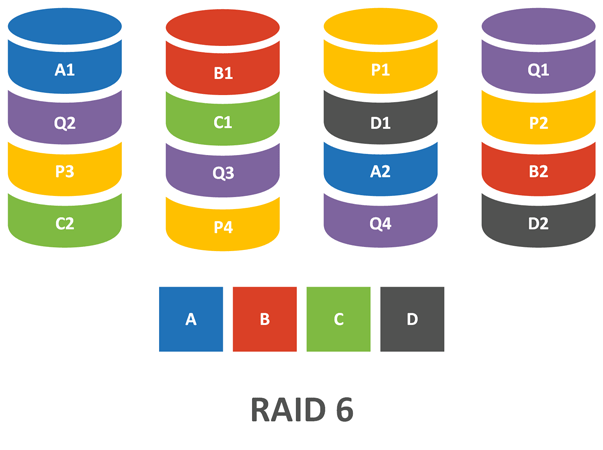
Казалось бы, вот он - новый компромисс, замена RAID 5 в современных условиях и т.д. и т.п., но за все надо платить. Одна операция записи на такой массив требует большего количества операций внутри массива: чтение данных, чтение четности 1, чтение четности 2, запись данных, запись четности 1, запись четности 2 - итого 6 операций, таким образом пенальти RAID 6 равен шести.
В общем, повысив надежность, данный массив существенно потерял в производительности настолько, что многие поставщики не рекомендуют его использование кроме как для хранения холодных данных.
И снова вернемся к мифам: RAID 6 это "круто"? Может быть, во всяком случае за свои данные можно не беспокоиться. А почему так медленно? Так это плата за надежность...
RAID 6E
По сути, тоже самое, что и RAID 5E. Резервный диск точно также распределяется в виде неразмеченного пространства в конце дисков, с теми же самыми ограничениями - один раздел на один массив. Ну и добавьте еще один диск в минимальное количество для массива, для RAID 5E это было 4, для RAID 6E - 5.
RAID 50 и RAID 60
Комбинированные массивы, аналогичные RAID 10, только вместо зеркала используется чередование нескольких массивов RAID 5 или RAID 6. Основная цель при создании таких массивов - более высокая производительность, надежность их в минимальном варианте соответствует надежности внутреннего массива, но в зависимости от ситуации может выдерживать отказ и большего количества дисков.
Заключение
Данная статья в первую очередь предназначена для исключения пробелов в знаниях и не претендует на какие-либо рекомендации. Тем не менее кое какие выводы можно сделать. RAID 5 в современных условиях применять не следует, скорее всего вы потеряете свои данные в любой нештатной ситуации.
RAID 10 остается наиболее производительным массивом, но имеет большие накладные расходы - 50%.
RAID 6 имеет наиболее разумное сочетание надежности и накладных расходов, но его производительность оставляет желать лучшего.
При этом мы оставили за кадром многие технологии, скажем RAID DP - реализацию RAID 6 от производителя систем хранения NetApp, которая предлагает все достоинства RAID 6 вкупе в высокой производительностью, на уровне RAID 0. Или RAID-Z - систем на основе ZFS, которые являются программными реализациями и для обзора которых потребуется отдельная статья.
Также мы надеемся, что данный материал поможет вам в осознанном выборе уровня RAID-массива согласно вашим требованиям.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:
![]()
Или подпишись на наш Телеграм-канал: ![]()