Как правильно организовать резервное копирование и спать спокойно
Пожалуй, нет другой такой темы, которая бы была столь заезжена - о резервном копировании не писал только ленивый. Она с завидной постоянностью поднимается во всех технических обсуждениях, про нее слагают анекдоты. Но, парадокс! Как только дело доходит до восстановления, то выясняются очень неприглядные вещи, начиная от отсутствия резервной копии и заканчивая тем, что копия вроде бы как есть, только вот... А работа стоит, предприятие несет убытки... Поэтому сегодня мы предлагаем вам поговорить о резервном копировании: что это вообще такое и как правильно организовать этот процесс, чтобы потом можно было спать спокойно.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Основной причиной написания данной статьи стал пожар в датацентре крупнейшего европейского хостинг-провайдера OVH. В ночь на 10 марта 2021 года огонь полностью уничтожил датацентр SBG2, частично выгорел SBG1, еще два датацентра не пострадали, но были отключены. Список пострадавших крайне широк: это правительственные ресурсы Франции, Великобритании, Польши, крупные европейские медиа-ресурсы, промышленные предприятия, спортивные клубы, разработчики ПО и т.д. и т.п. Последствия тоже различные: так, например, шахматный интернет-сервис Lichess.org отделался "легким испугом".
В Twitter-аккаунте шахматного сайта Lichess.org сообщается, что в пожаре сгорело несколько серверов Lichess. Впрочем, благодаря усердию сисадмина, который позаботился о резервном копировании, потери данных удалось минимизировать - утрачена история шахматных задач только за последние 24 часа.
А вот некоторым повезло меньше, разработчик игр Rust потерял все свои данные:
"Мы подтверждаем полную потерю серверов из-за пожара в центре обработки данных OVH. Мы изучаем возможность замены оборудования. Восстановление данных невозможно", - сообщение Rust в Twitter.

Но это крупная авария, которая у всех на слуху, а сколько инцидентов с потерей данных происходит ежедневно за закрытыми дверями различных организаций? Причем одного такого случая бывает достаточно, чтобы лишиться рабочего места или поставить крест на карьере, независимо от предыдущих заслуг. Поэтому давайте уделим вопросу резервного копирования самое пристальное внимание, а начнем с самого начала.
Резервная копия, архив и синхронизация - в чем разница?
Прежде всего необходимо навести порядок в терминологии и разобраться что такое резервная копия и для чего она нужна. Резервная копия - это копия данных предназначенная для восстановления информации в случае утери рабочей копии по какой-либо причине. Это определение следует крепко-накрепко запомнить и вспоминать всегда, когда будут появляться задачи по резервному копированию данных.
Еще раз - резервная копия предназначена только для восстановления данных и ни для чего иного. Очень часто резервную копию путают с архивом, но это принципиально разные сущности. Что такое архив? Это срез данных на определенную дату, который предназначен для хранения и контроля, к вопросу восстановления данных он никакого отношения не имеет. Время от времени мы слышим, что нужно делать копии данных каждый квартал, полугодие, год и хранить их в течении трех - пяти лет. Многие администраторы воспринимают это как создание еще одного набора резервных копий, хотя на самом деле фактически речь идет о создании архива.
В чем разница? В отличие от резервной копии, архив - это рабочая копия данных, в правильности и достоверности которых мы уверены. Скажем в бухгалтерском учете такой операцией может являться закрытие месяца, квартала, полугодия, года. После чего мы можем быть уверены, что данные в базе соответствуют реальному положению дел и ее можно отправлять в архив. Таким образом копия сделанная 31 марта не будет являться архивом за квартал, так как все необходимые регламентные операции еще не выполнены и в достоверности данных мы не уверены.
Еще одна популярная технология, которая используется для создания копии данных - синхронизация. Как правило - это быстро и удобно. Но является ли это резервным копированием? Нет! Почему? Для ответа на этот вопрос подумаем, что может произойти с нашими данными. Они могут быть уничтожены, а могут быть повреждены или искажены, в том числе и неумышленно. В случае с использованием синхронизации в копию попадут искаженные или поврежденные данные и восстановить информацию из нее не будет представляться возможным.
Значит ли это, что не синхронизацию использовать не следует? Отнюдь, просто нужно понимать, что это не способ резервного копирования, а один из методов повышения отказоустойчивости, как RAID. В случае аппаратного отказа основного узла у нас на руках будет практически на 100% идентичная копия, которая позволит быстро восстановить работу сервиса. Но от ошибочных действий с данными или атаки вируса-шифровальщика синхронизация нас не спасет.
Исходя из вышесказанного следует понимать: резервная копия - это срез данных на определенный момент времени, который позволяет выборочно или полностью вернуться к этому состоянию. Поэтому важно поддерживать целостность и неизменность резервного набора данных, как правило это достигается помещением его в определенный контейнер: zip-архив, образ системы, теневая копия и т.д. и т.п.
Как часто и в каком объеме копировать?
На первый взгляд тут все просто: копируем всё, как можно чаще и храним как можно дольше. Вроде бы все хорошо? На самом деле не очень. Хотя именно этот подход очень часто используется во многих организациях. А что? Копии есть, копий много, можно спать спокойно. Такие требования могут даже встречаться в договорах и должностных инструкциях. Например, в проект одного из договоров заказчик попытался включить следующее:
Резервное копирование баз данных исполнитель производит не реже одного раза в день. Резервные копии хранятся не менее трех лет.
При этом со стороны заказчика так никто и не смог пояснить, зачем им резервные копии трехлетней давности, просто где-то нашли подобную формулировку, и она показалась им подходящей. Все это приводит к тому, что резервное копирование производится только ради резервного копирования, не учитывая реальных угроз и потребностей предприятия.
В данной ситуации следует отталкиваться от следующего тезиса: стоимость резервного копирования не должна превышать возможный ущерб от потери данных.
Под стоимостью здесь подразумеваются как одноразовые, так и текущие затраты на систему создания и хранения резервные копий. Непонимание этого момента приводит к появлению противоречий между техническим персоналом и владельцами бизнеса, в результате которых последний может остаться без резервного копирования вообще. Если фирма использует базу данных только для вставления счетов и оформления отгрузочных документов, то ее потеря будет, конечно, досадным недоразумением, но не более. Подойдет копия практически любой давности, а остальное можно будет внести заново руками.
Но это не значит, что такие фирмы следует оставлять без резервного копирования, просто его объем и частота должны быть адекватны характеру бизнеса и реальным угрозам. Вполне достаточно будет делать копию в облако допустим раз в сутки. Так как объем изменения данных небольшой, то мы можем позволить себе откат даже на несколько дней назад, скажем, если возникла ошибка по вине человека, и она не была замечена сразу, потому как внести самим документы за несколько дней для организации может оказаться дешевле, чем услуги специалиста по исправлению ошибок в учете. Поэтому мы можем смело хранить неделю, вряд ли больше. В данном случае глубину может дополнительно ограничивать бесплатный тариф облачного хранилища.
Данный пример, может показаться кому-то крайностью, но мы специально привели его для того, чтобы показать, что адекватный угрозам процесс резервного копирования можно организовать и при практически полном отсутствии бюджетов.
Если же речь идет о крупной фирме, с большим количеством сотрудников, отделов и филиалов - то даже незначительный простой будет для нее очень болезненным, а потери данных за сутки могут потребовать гораздо большее количество времени на восстановление. Также мы столкнемся с большим объемом данных и высокой скоростью их изменения.
Простые способы здесь не работают, либо оказываются неэффективными, а чаще всего - и то, и другое. В результате может сложиться очень печальная ситуация, когда на систему резервного копирования были потрачены значительные средства, но в критической ситуации она оказалась бесполезной, при том, что технически все сделано вроде бы правильно. Почему так происходит? Да потому что резервное копирование настроено по одной из типовых инструкций, без учета реальных угроз и требований.
Поэтому первоначально нужно составить список угроз и только потом выбирать наиболее эффективный механизм для противодействия им. Начнем с наиболее очевидных: потеря рабочей копии данных по каким-либо причинам. При этом под потерей мы подразумеваем не только физическую утрату копии данных, но и необратимое логическое изменение структуры, которое невозможно устранить в короткие сроки (удаление, изменение реквизитов документов и т.д. и т.п.). В этом случае нам нужно как можно скорее восстановить рабочую копию с минимальной потерей информации.
От физической потери копии без изменения структуры данных (отказ носителя, выход из строя сервера) нас может подстраховать синхронизация, в этом случае у нас будет запасной экземпляра рабочей копии, на который мы можем переключиться немедленно. Но он не спасет нас в случае логического повреждения рабочего набора данных. Для этого нам нужна резервная копия. Она должна быть полной и позволять быстро восстановить работоспособность рабочей копии.
Как часто нужно создавать такую копию? Здесь все зависит от того объема информации, который допустимо потерять с одной стороны и затратами на создание и хранение копий с другой. Допустим, в качестве такого интервала мы выбрали час. Сколько копий нам нужно хранить? Немного. По большому счету нам будет нужна только одна копия - последняя, ну может быть одна из предпоследних, если изменения в данных заметили не сразу. Копия давностью в сутки для целей восстановления фактически бесполезна. Хорошим вариантом будет делать резервную копию каждый час в период рабочего времени и перезаписывать их по кругу.
Будет ли этого достаточно? Нет. Потому что мы создали только один - оперативный контур, который позволит нам быстро восстановить рабочую копию данных при ее критическом повреждении здесь и сейчас. Однако существуют и другие угрозы. Например, изменения данных задним числом, либо их повреждение. Чаще всего такие ошибки не связаны с физическими повреждениями данных, а имеют причиной человеческий фактор и ошибки в ПО. В этом случае нам нужна копия данных за период сравнимый с глубиной повреждения данных, позволяющая развернуть копию с заведомо достоверной информацией. В этом плане нам очень может помочь архив. Как мы помним, туда попадают данные после закрытия соответствующего периода.
Скажем в мае бухгалтер говорит нам, что поплыли данные за февраль. ОК, разворачиваем архив за первый квартал и анализируем изменения. Однако одного архива может оказаться недостаточно, бывают ситуации, когда данные были изменены в течении более короткого промежутка времени: нескольких дней, недели. Для этого нам потребуется еще один контур резервного копирования, цель которого не быстрое восстановление рабочей копии, а получение ее рабочего экземпляра на предыдущую дату для целей анализа и выборочного восстановления. В этом случае мы можем делать копии каждый день в течении недели, каждое воскресенье за неделю и каждый последний день месяца за месяц.
При этом следует понимать, что это две разных задачи по резервному копированию и они должны выполняться полностью самостоятельно и у каждой из них должны быть свои выделенные ресурсы. Например, чтобы закончившееся место на разделе с ежедневными копиями не могло повлиять на возможность создавать оперативные копии каждый час. Или ошибка в скрипте не оставила вас вообще без резервных копий.
Это как раз та область, где простота только приветствуется, чем сложнее схема - тем больше ошибок может в ней возникнуть и тем сложнее ее контролировать. Набор простых заданий хорош тем, что даже если сломается одно из них - остальные будут продолжать работать. Ну и не забывайте про ресурсы. Вместо одного общего хранилища выделите под каждый набор данных собственное: отдельные диски, разделы, виртуальные или iSCSI-диски, дисковые лимиты в конце концов.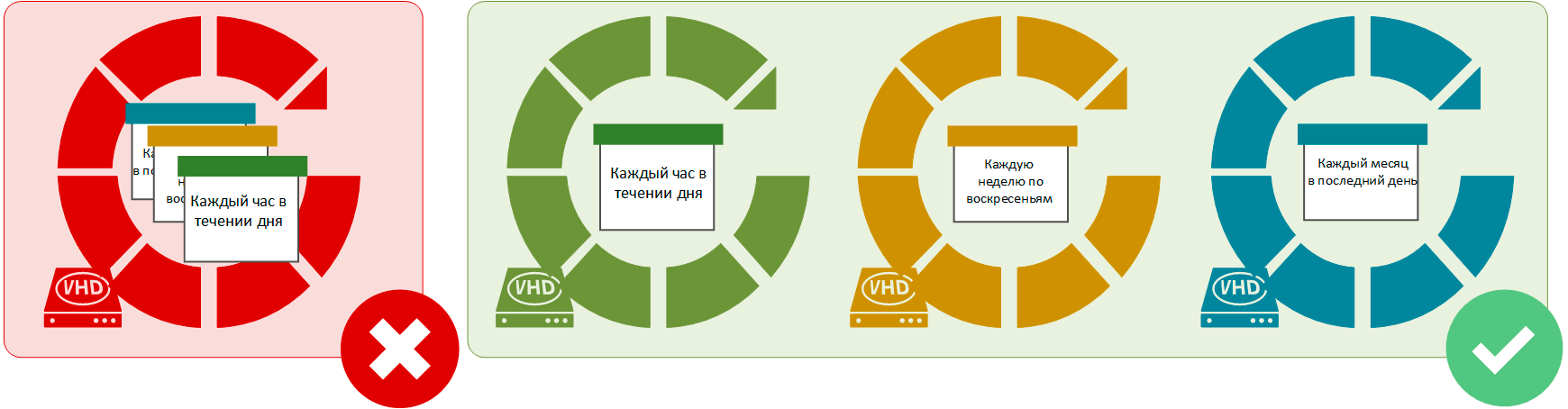
Что именно копировать?
На первый взгляд вопрос глупый. Как что? Данные. Но это очень размытое понятие, так как данными является практически все, что хранится на ваших дисках, но разные данные имеют различную критичность, которая может меняться от ситуации к ситуации. Неверное понимание этого вопроса также может привести к ситуации, когда бекапы есть, но воспользоваться ими вы не можете, либо это займет продолжительное время (в ряде случаев это равносильно тому, что бекапов нет). Как так может произойти? Давайте разбираться.
Возьмем следующий пример: у нас есть виртуальная машина с некоторым сервисов внутри, скажем сервером СУБД. Какие варианты резервного копирования нам доступны? Прежде всего копирование самой виртуальной машины. Вариант хороший, многие на этом и останавливаются, забывая о сценариях, когда восстановить виртуалку будет невозможно. Аптайм серверных систем достаточно велик, а многие ошибки проявляют себя только после перезагрузки, таким образом можно получить копии, которые сняты с работоспособной машины, но загрузиться они не смогут. Да, в большинстве случаев ОС можно восстановить, но это дополнительные затраты времени в и без того критической ситуации, одним словом пожар во время наводнения. Да и все может оказаться гораздо проще - нет запасного гипервизора.
В этом случае нам нужно иметь копию данных из виртуальной машины, в случае с СУБД это может быть полный дамп сервера. После чего нам достаточно поднять экземпляр нужной СУБД и загрузить данные в нее. При этом риски что-то забыть или потерять минимальны, что важно если на вашем сервере большое количество баз, с разными владельцами и разными правами доступа.
Но бывают и иные ситуации, когда нам нужно восстановить одну единственную базу, либо нет возможности поднять новый экземпляр СУБД, но есть уже существующий, в который вполне можно загрузить нужные базы. Для этого нужно иметь дампы баз данных по отдельности. Да, их можно выгрузить располагая полным дампом или образом ВМ, но это снова дополнительное время и необходимость в дополнительных ресурсах.
И наконец то, о чем многие забывают. Настройки! Мы многократно были свидетелями возникновения аварийных ситуаций только от того, что администратор пошел вносить изменения в настройки работающего сервиса, не сделав их копии. А теперь представим, что у вас были достаточно сложные персонализированные настройки для СУБД или веб-сервера, без них восстановить работоспособность сервиса в полной мере не удастся, даже при наличии всех остальных данных.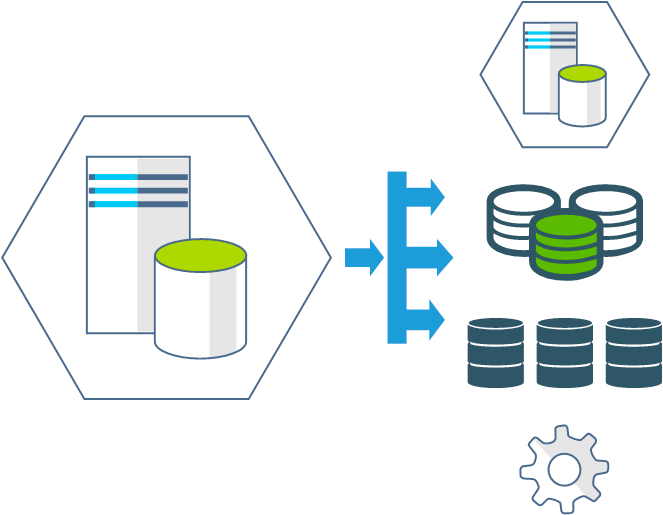
Таким образом правильная организация резервного копирования предполагает наличие копий данных на разных уровнях абстракции: виртуальная машина, дамп сервера БД, каждая БД отдельно и т.д и т.п. А также обязательное копирование настроек, для этих целей неплохо подходят системы контроля версий (git и т.п.), что позволяет не только иметь их копию, но и отслеживать всю историю изменений, с возможностью быстрого отката.
Где и как хранить копии?
Когда мы говорим об организации хранения копий, то чаще всего вспоминается правило 3-2-1, которое гласит, что нужно хранить три резервные копии, в двух разных физических форматах хранения, одну из них за пределами офиса (существуют разные формулировки этого правила, но общий смысл от этого не меняется). Любое хорошее правило возникает не на пустом месте, а воплощает в себе пользовательский опыт, зачастую негативный. И если говорят, что правила техники безопасности написаны кровью, то правила резервного копирования созданы опытом потери данных.
Но не следует воспринимать данное правило, как догму, также как следовать иным распространённым аксиомам, скажем, не хранить резервные копии на самом же сервере, потому как из любого правила допустимы исключения.
Все должно следовать той же логике анализа угроз и способов им противодействовать. Резервные копии должны не только храниться в надежном месте, но и быть доступны в случае необходимости. Что толку в копии виртуальной машины на удаленном хостинге если копироваться она оттуда будет несколько часов, а восстановить одну из нескольких СУБД нужно здесь и сейчас.
Вопреки распространённому мнению последний экземпляр копии в несжатом виде можно и нужно хранить на самом сервере, это позволяет приступить к процессу восстановления немедленно, а в ряде случаев такая копия просто необходима, например, если вы решили провести некоторые технические работы. Копировать ее в хранилище нет никакого смысла, так как ее цель - страховка от ошибочных действий здесь и сейчас.
Копии для оперативного восстановления должны располагаться в пределах сети предприятия, но в отдельном хранилище, желательно физически разнесенном с защищаемыми серверами. Либо хранилищ может быть несколько, одно прямо в серверной, с быстрыми каналами связи, другое, более медленное, в другом корпусе или даже в филиале.
Что касается облачных сред и хостинга, то его роль может выполнять хранилище или услуга, предлагаемая самим хостером, что обеспечит высокую скорость восстановления при необходимости.
Теперь о форматах. Копию для непосредственного восстановления данных лучше всего хранить в родном формате защищаемого приложения, желательно без сжатия, так как наша цель не экономия хранилища, а максимально быстрое восстановление. Для баз данных это может быть дамп средствами самой СУБД. Но могут быть ситуации, когда рабочего экземпляра СУБД нет, а данные восстановить надо. Это важно для приложений, которые могут использовать различные СУБД и платформы для работы. Скажем вместо аварийного сервера с PostgreSQL на Linux у вас есть работающий MS SQL на Windows. Для этих целей нужно иметь выгрузку данных в универсальный формат для восстановления на любой платформе, это может быть как родной формат приложения, так и некоторый универсальный, скажем XML.
Таким образом мы уже получаем две резервные копии в двух различных форматах хранения. Одна в сыром виде на самом сервере, вторая в двух форматах в локальном хранилище.
Третья копия должна располагаться удаленно, и она нам потребуется только тогда, когда локальные копии окажутся недоступными, как правило - это какая-то чрезвычайная ситуация (пожар, затопления и т.д.) и здесь уже важен сам факт ее наличия. Скорость доступа и формат особой роли не играют, хотя, если есть такая возможность, хранить следует несколько копий в различных форматах хранения. Хранится они должны у отдельного провайдера и в совершенно иной локации чем ваш остальной хостинг или виртуальные сервера, даже если у текущего провайдера вас все устраивает.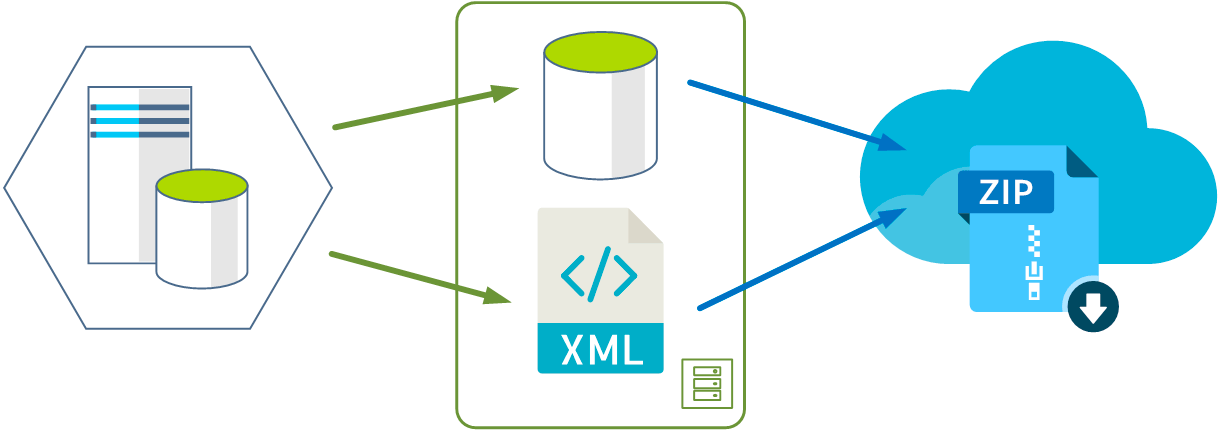
Почему? Хороший пример - пожар в датацентре OVH, с которого мы начали статью. Также можно вспомнить "споры хозяйствующих субъектов", которые привели практически к полной остановке работы хостера Айхор с физическим отключением и вывозом серверов. Также следует иметь ввиду техногенные аварии и природные катаклизмы, которые могут привести к проблемам во всем регионе.
Промежуточный итог
Как мы только что выяснили - резервное копирование - это сложный и многоступенчатый комплекс мероприятий, направленный на противодействие различным угрозам информационной инфраструктуре. Копии не просто должны быть, а соответствовать возможным угрозам и удовлетворять требованиям по быстрому восстановлению информации, что подразумевает различные способы копирования и форматы хранения данных. Кроме того, не следует забывать, что кроме самих данных в резервном копировании нуждаются и настройки.
Например, мы неоднократно сталкивались, что при достаточном объеме системы хранения и выделенных гигабитных каналах дампы БД хранились сжатыми неэффективным 7Zip, который долго сжимает, долго распаковывает и сильно нагружает при этом процессор. При этом частота резервного копирования была явно недостаточной, т.к. архиватор тратил на упаковку около 20 минут, и пользователи жаловались на снижение производительности системы. Налицо неверный выбор архиватора, основанный на степени сжатия, а не на эффективности и скорости работы.
Другой пример: архив 1С: Предприятия хранится в формате дампов СУБД, а не выгрузки самой 1С. В итоге при необходимости развернуть архивную базу локально или на сервере с иной системой управления базами данных администратору сначала потребуется развернуть дамп, подключить базу и сделать из нее выгрузку в формат 1С:Предприятия.
Зеркальная ошибка - хранение резервных копий только в формате выгрузки 1С (DT-файлы), хотя сам разработчик предупреждает, что данный формат не предназначен для резервного копирования, так как ряд ошибок могут не препятствовать выгрузке, только вот загрузить такую копию уже не удастся. Тоже самое можно отнести и копиям виртуальных машин.
Поэтому форматов хранения резервных копий должно быть несколько, в расчете на разные сценарии восстановления, пусть даже для этого придется пожертвовать глубиной хранения, которая в большинстве случаев не нужна, а вопрос доступа к данным прошлых периодов должен решать архив. Если же вам требуется большая глубина хранения больших объемов данных - скорее всего вы неверно решаете поставленную задачу.
Как-то раз мы помогали одному нашему заказчику решать проблему резервного копирования файлового сервера с общим объемом данных около 2 ТБ и весьма серьезными требованиями по глубине хранения копий. Попытка копировать все и сразу вполне ожидаемо не увенчалась успехом, начиная с вопросов, где это все хранить и заканчивая временем необходимым для этой процедуры.
Поэтому мы предложили зайти с другой стороны и посмотреть, что именно там хранится. Оказалось, что большая часть файлов (по размеру) представляет собой архив конструкторской документации, которую вообще следует перевести в режим только чтение, а любые изменения оформлять как новые версии документов. Далее выяснилось, что определенные наборы документов должны быть доступны для записи только для определенных отделов, скажем договора могут корректировать только юристы, остальным они также должны быть доступны только на чтение. Таким образом удалось разделить одну "неподъемную" задачу на ряд более простых, с гораздо меньшими объемами копируемой информации, а также, в качестве "бонуса", упорядочить работу с информацией и правила доступа к ней.
Резервные копии нужно проверять
Этого момента мы несколько раз коротко касались выше, говоря о том, что ряд форматов не обеспечивает гарантированного восстановления информации, при этом, не вызывая ошибок при выгрузке. Кроме того, к повреждению копий могут приводить различные внешние факторы, которые вы можете заметить далеко не сразу. Поэтому копии нужно проверять. И делать это не время от времени, а регулярно. К счастью, это несложно автоматизировать. При ошибках восстановления весь лог должен быть отправлен на почту ответственному лицу.
По важности такая ситуация превосходит ошибку при создании резервной копии и требует немедленной реакции, потому как может обозначать, что вы остались без резервных копий вообще. Частоту проверок следует выбирать согласно критичности проверяемых данных. Чем критичнее для предприятия хранимые данные - тем чаще нужно делать проверки.
Еще один важный аспект регулярных проверок - это получение реальных данных о времени и ресурсах необходимых для данной процедуры. Поэтому нужно логировать не только неудачные попытки восстановления, но и успешные, с обязательным регулярным анализом. Именно анализ времени восстановления позволил одному из наших заказчиков своевременно выявить деградацию RAID массива в недорогом NAS, когда резко увеличилось время чтения с устройства хранения, хотя сам NAS продолжал считать, что у него все нормально.
В другом случае удалось своевременно выяснить, что текущий размер базы не позволяет загрузить ее на 32-битном сервере, это позволило своевременно спланировать и провести апгрейд, не дожидаясь пока это станет причиной нештатной ситуации.
А как насчет плана восстановления?
"Какие еще планы, - махнет рукой системный администратор, - и так работы выше крыши". Но будет не прав. Критическая ситуация всегда развивается непредсказуемо и характеризуется высоким уровнем стресса, добавьте сюда еще давление от руководства, глупые вопросы коллег - в такой атмосфере немудрено что-нибудь забыть или сделать не так. А еще все это может произойти в ваше отсутствие.
Что такое план восстановления? Это детально и максимально подробно описанная процедура восстановления рабочей копии данных из резервной. Своего рода пошаговая инструкция, дословно выполнив которую любой специалист достаточного уровня сможет произвести восстановление данных. При этом внести в нее нужно всё, в том числе и банальные, очевидные на первый взгляд, вещи. Потому что в условиях стресса это может вылететь из головы, а еще, то что "очевидно" для вас, не всегда является очевидным для ваших коллег.
Простой пример: вы внедрили в качестве архиватора современный и эффективный Zstandard и поехали в отпуск, когда вы были не на связи вашему коллеге потребовалось восстановить данные из копии. Допустим, даже ничего серьезного, нужно было вернуть все назад после неудачных технических работ. Но тут его поджидал сюрприз в виде неизвестного ему формата zst. В итоге время было потрачено на то, чтобы выяснить что это такое и как с этим работать, работы вышли за рамки технологического окна, возник простой и руководство выразило недовольство работой IT-службы. Но всего этого можно было бы избежать, если бы это было где-то отражено в документации.
Еще один важный момент - план восстановления всегда должен иметься в виде печатной копии. Потому что ситуации бывают разные и лучше достать из папки бумажную копию, чем судорожно гуглить на телефоне нужные команды и ключи к ним. В любом случае наличие плана позволит начать действовать системно и упорядоченно, что очень важно в условиях общей нервозности или даже паники.
Кроме того, сам процесс составления плана позволяет выявить недоработки в системе резервного копирования, узкие места, потенциальные проблемы. В этом нет ничего зазорного или порочащего, ошибаться, либо неверно оценивать необходимые ресурсы свойственно всем, лучше если это будет исправлено еще на этапе планирования, нежели вы столкнетесь в этим в критической ситуации.
И последнее, составив план не забудьте провести по нему "учения", это не только позволит оценить соответствие теории практике, но и получить практические навыки восстановления данных. И даже если учения закончатся неудачей, то это не повод для уныния, а, наоборот, весьма ценный и полезный опыт, анализ которого позволит устранить выявленные недостатки. Такие учения следует время от времени повторять, как для закрепления навыков, так и для проверки того, что текущие условия позволят вам успешно выполнить план.
Выводы
Данный материал получился достаточно обширным и в то же время обобщенным. Мы не касались конкретных сценариев и примеров, стараясь говорить об общих принципах. Понятно, что все вышесказанное не всегда можно воплотить в жизнь в полном объеме, но данная статья должна стать больше информацией для размышления и оценки текущего состояния дел. Мы будем рады, если вы сможете по-новому взглянуть на процесс резервного копирования и привести его в состояние адекватное возникающим угрозам, а не делать копии ради копий.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:
![]()
Или подпишись на наш Телеграм-канал: ![]()