Замена сбойного диска в массивах ZFS
ZFS все чаще применяется в системах хранения Linux благодаря своим широким возможностям и отличной надежности. Но очень часто пользователи не имеют практических навыков работы с этой файловой системой, отдавая работу с ней на откуп вышестоящим системам, например, системе виртуализации Proxmox. Первые сложности начинаются когда пользователь сталкивается с необходимостью обслуживания ZFS и не находит для этого графических инструментов. Одна из таких задач - это замена сбойного диска в массиве, задача серьезная и ответственная, но в тоже время простая. В этой статье мы расскажем как это сделать.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Как известно, нет ничего вечного и дисковые накопители не исключение. Они вырабатывают ресурс, выходят из строя, часто внезапно. Чтобы уберечь себя от подобных рисков давно были придуманы массивы с избыточностью, когда информация дублируется на несколько дисков и в случае отказа одного из них у нас останется рабочая копия, а мы сможем спокойно и без особых проблем заменить сбойный диск.
ZFS не исключение, сегодня она широко используется для хранилищ разного уровня и очень часто используется "из коробки", без полного понимания работы. Именно так, чаще всего, происходит в системе виртуализации Proxmox. Там можно легко создать ZFS в графическом интерфейсе, но практически невозможно им управлять и когда пользователь видит отказавший диск, то сразу возникает вопрос: что делать? Отказавший диск есть, а никаких инструментов работы с ним нет.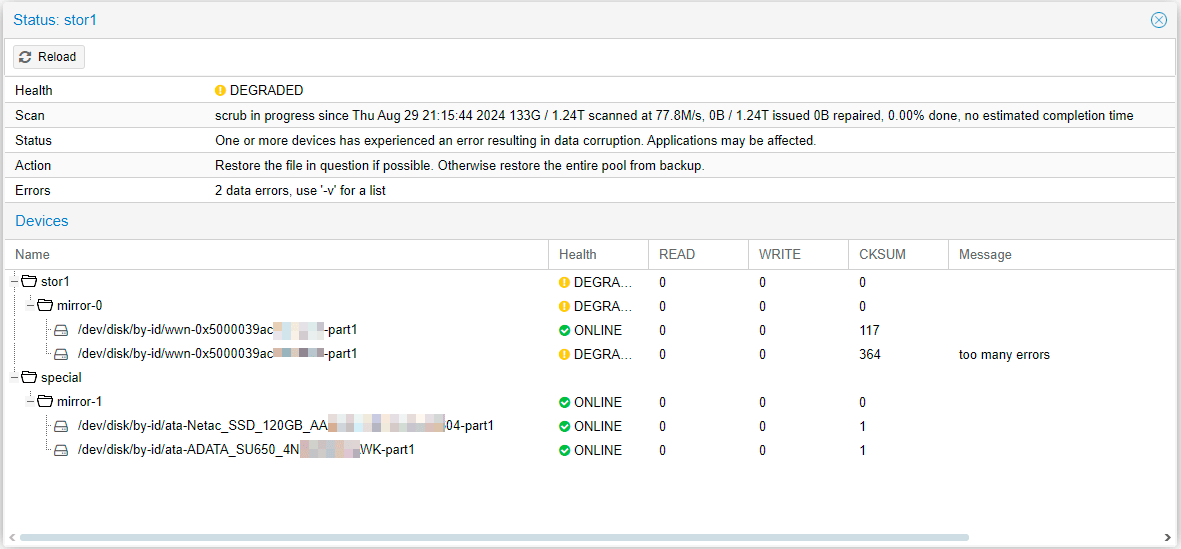
Прежде всего не паниковать. Вся основная работа по администрированию Linux производится в консоли, веб-панели - это просто приятное дополнение, не более. Поэтому переходим в консоль с правами суперпользователя (root) и первым делом получаем список хранилищ (пулов) ZFS:
1zpool list
После чего вы получите примерно такой вывод: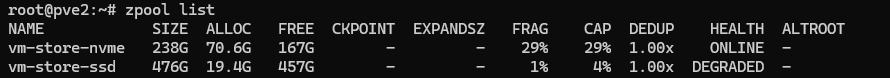
Из чего мы делаем вывод, что у нас в данной системе два пула, один исправный - ONLINE, второй с отказавшей избыточностью - DEGRADED.
Теперь получим информацию о деградировавшем пуле:
1zpool status vm-store-ssd
Где vm-store-ssd - имя интересующего нас пула.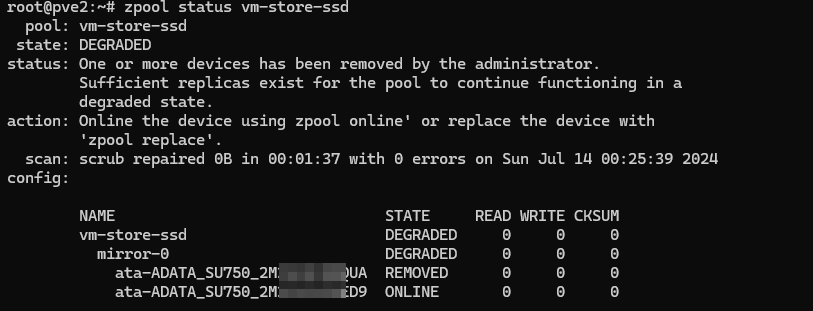
Как видим, отказавший массив содержал два диска, один из которых уже физически извлечен (REMOVED), ZFS оперирует именами дисков по id и идентификатор, как правило, уже содержит серийный номер, что позволяет быстро идентифицировать отказавший диск.
Если же диск окончательно вышел из строя и не определяется, либо определяется как-то не так, то рядом с диском будет указано как он именовался до того, как перестал работать.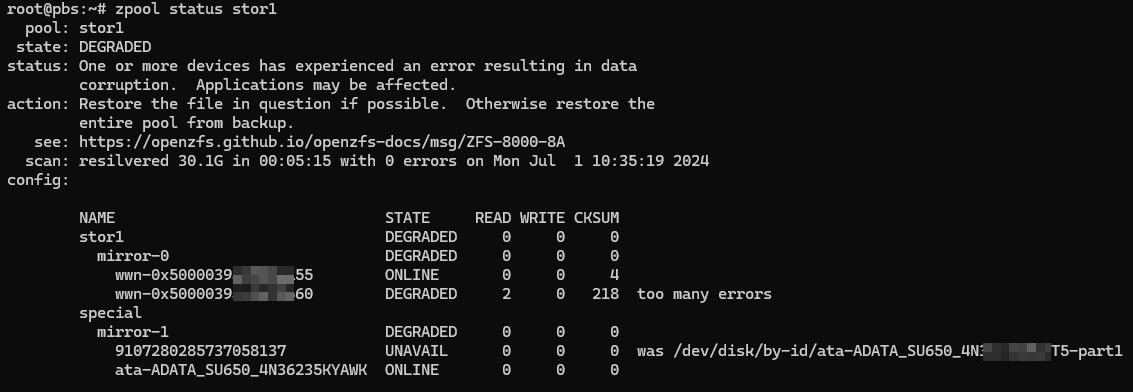
Такой диск помечается как UNAVAIL - недоступный, если же помеченный сбойным диск присутствует в системе и продолжает работать, то он помечается как DEGRADED.
В целом разобрались, id чаще всего содержит серийный номер диска, что позволяет быстро идентифицировать виновника на физическом уровне. Но обратите внимание на две записи на скриншоте выше.
1wwn-0x5000039***55
2wwn-0x5000039***60
Никакими серийниками тут и не пахнет, поэтому давайте узнаем на какие именно физические устройства указывают данные идентификаторы.
1ls -al /dev/disk/by-id
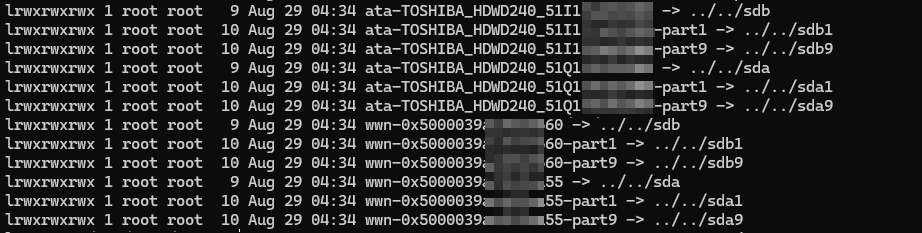
Вот теперь сразу становится понятно, что:
1wwn-0x5000039***55 -> ata-TOSHIBA_HDWD240_51I1*** -> ../../sdb
2wwn-0x5000039***60 -> ata-TOSHIBA_HDWD240_51Q1*** -> ../../sda
Если данные тома не содержат корневой файловой системы, а такой случай мы в данной статье не рассматриваем, то просто выключаем сервер, удаляем сбойный накопитель и ставим на его место новый. Загружаемся, узнаем id нового диска той же командой:
1ls -al /dev/disk/by-id
Теперь можем выполнить замену, для чего вам потребуется всего одна команда:
1zpool replace vm-store-ssd /dev/disk/by-id/ata-ADATA_SU750_2M***UA /dev/disk/by-id/ata-Netac_SSD_512GB_AA***68
В нашем случае мы заменили в пуле vm-store-ssd отказавший диск ata-ADATA_SU750_2M***UA на новый диск ata-Netac_SSD_512GB_AA***68.
Теперь вам остается только дождаться окончания синхронизации. ZFS - умная система и не синхронизирует нули, поэтому данный процесс будет зависеть только от объема реальных данных на накопителе. Посмотреть состояние процесса можно командой:
1zpool status vm-store-ssd
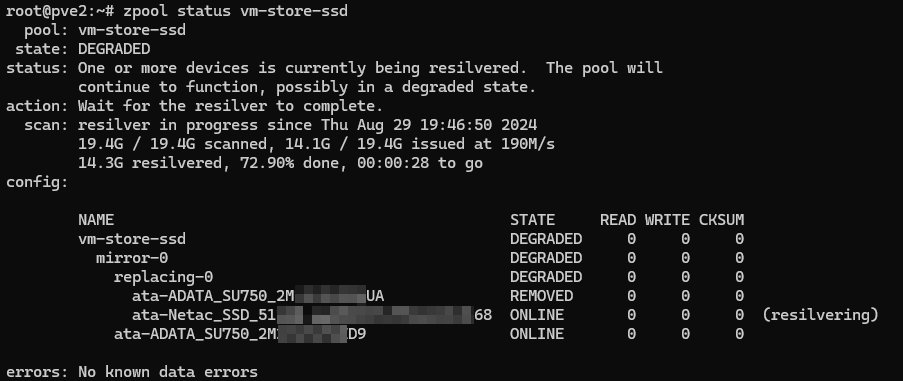
После синхронизации можно сбросить ошибки массива выполнив:
1zpool clear vm-store-ssd
Как видим, заменить сбойный диск в массиве ZFS совсем не сложно, главное - быть внимательным и правильно определить нужное физическое устройство.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:
![]()
Или подпишись на наш Телеграм-канал: ![]()