Zabbix - основы и базовые понятия
Zabbix - сложная система и у начинающего пользователя часто разбегаются глаза и он теряется среди новых для него терминов и обилия информации. Поэтому, прежде чем браться за ее освоение, нужно изучить базовые понятия и основы построения системы, чтобы понимать из каких элементов, как из кирпичиков, строится мониторинг. Данная статься рассчитана на начинающих, но также будет полезна и тем, кто уже работает с Zabbix так как поможет освежить и систематизировать знания, а может быть даже и узнать что-то новое.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Узел сети
Весь мониторинг в Zabbix строится вокруг узлов сети (Host) которые являются объектами наблюдения. Каждый узел сети является некоторой сущностью - физическим компьютером, сетевым устройством, виртуальной машиной или некоторым приложением. Понятие о том, что может являться узлом сети у Zabbix очень гибкое, при желании можно мониторить практически все что угодно.
Каждый узел сети имеет свой сетевой адрес и может опрашиваться некоторым способом, например, при помощи Zabbix agent или SNMP, все способы мы приводить не будем, их много. Основной режим работы системы мониторинга - это пассивные проверки, когда сервер обращается к узлу сети и получает от него запрошенные данные. В качестве альтернативы могут быть настроены активные проверки, в этом случае агент самостоятельно обращается к серверу, получает он него список элементов для сбора данных, собирает их и самостоятельно передает серверу.
Узлы сети могут быть добавлены вручную или с помощью автоматического обнаружения, которое может по определенным условиям сканировать указанный диапазон сети, находить и добавлять обнаруженные узлы, а также удалять неактивные. Данной возможностью удобно пользоваться для обнаружения компьютеров мобильных пользователей, либо в тестовых средах, где вы постоянно создаете и удаляете новые сущности.
Узлы сети объединяются в группы, так как все права доступа назначаются только на группы, то каждый узел должен входить хотя бы в одну группу.
Элемент данных
Второй основной кирпичик системы мониторинга - элемент данных (Item), каждый элемент данных определяет одну метрику узла сети, а также правила сбора и хранения информации по выбранной метрике. Тип элемента данных зависит от типа собираемой информации, это может быть строка, число, булево значение и т.д. и т.п.
Существуют также вычисляемые элементы данных, которые не собираются с узлов сети, а вычисляются на основании других элементов, например, объем свободной или занятой памяти в % и т.п. При этом в базе Zabbix могут храниться значения только вычисляемых элементов, а взятые за основу сырые данные не сохраняются. Это связано с тем, что сырые данные могут поступать в неудобной для восприятия человеком форме и после вычисления нужного значения более не требуются.
Например, ниже показан элемент данных сырых значений загрузки процессора для роутера Mikrotik, данное значение сервер получает по SNMP и в базе не хранит. Здесь же мы можем увидеть, что данная метрика считывается раз в минуту и формат получаемых данных - текст.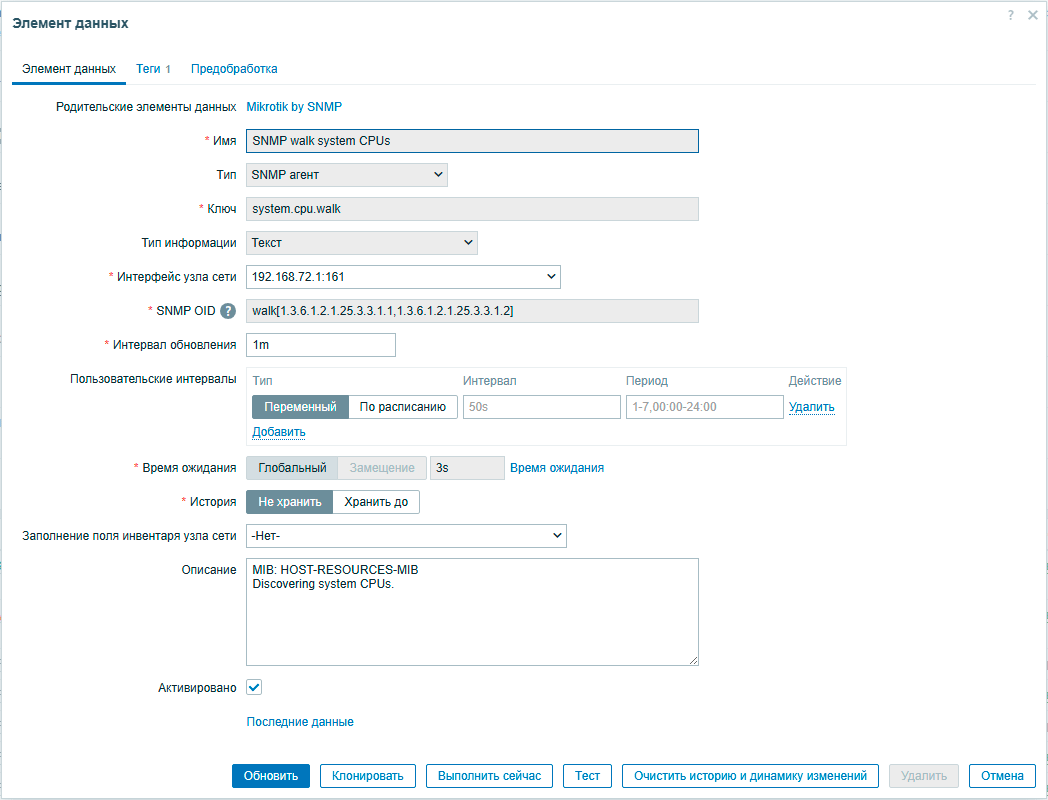
На основании этих данных вычисляется загрузка процессора в привычном нам числовом, процентном значении и именно она записывается и хранится в базе: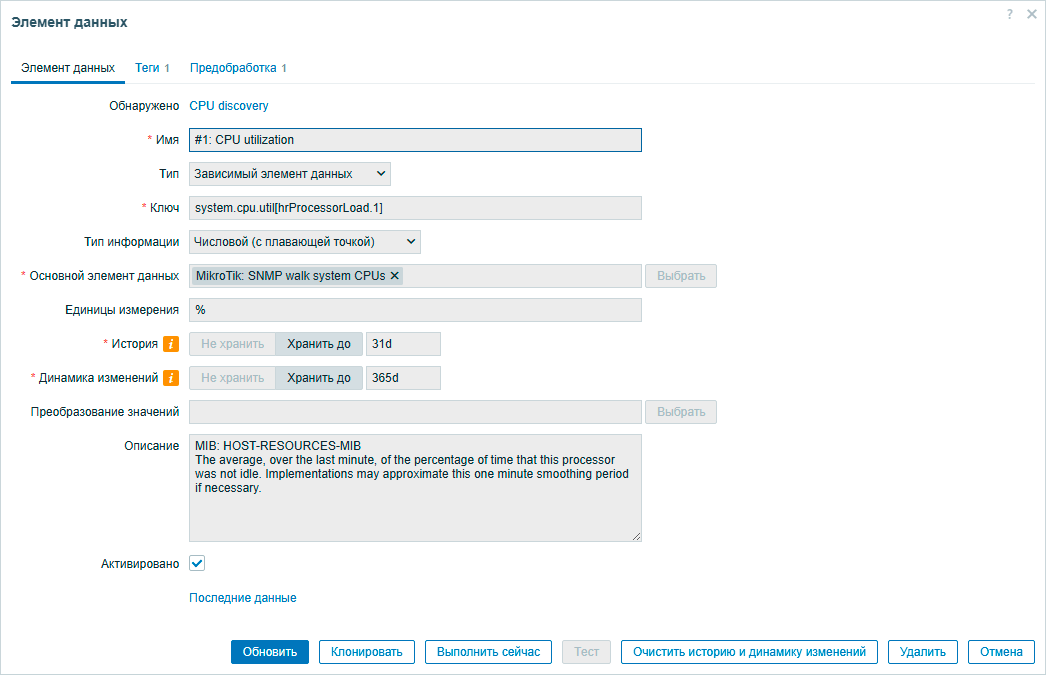
Здесь следует обратить внимание на два параметра хранения: История и Динамика изменений. История хранит сами значения мониторинга, а динамика изменений - их усредненные значения за час (хранится среднее значение, минимум и максимум), что гораздо менее ресурсоемко. Несложно подсчитать, что для хранения данных собираемых каждую минуту в течении 31 дня нам понадобится 44 640 записей в базе данных, а для хранения динамики изменений на протяжении года - всего 8 760 записей. Поэтому период хранения истории должен быть небольшим, достаточным ровно для того, чтобы была возможность по горячим следам расследовать инцидент или произвести тонкую подстройку под нагрузку, а хранить следует именно динамику изменений.
Еще одна возможность элементов данных Zabbix - это пропускать значения, если они не изменились. Например, информацию о версии прошивки роутера или имени узла. Такая информация считывается достаточно часто, раз в 1 час у того же Mikrotik, но в базу записывается только одно значение за день, если не было изменений, или два - если такие изменения были. В противном случае нам бы пришлось хранить 24 одинаковых записи.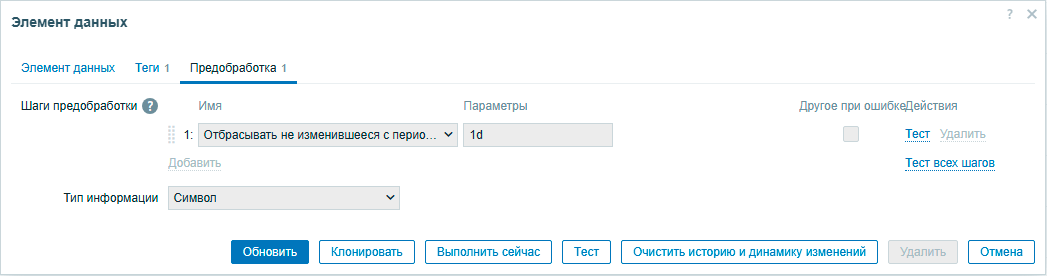
Также не следует путать элемент данных с самой метрикой, потому что кроме значения метрики он задает правила ее сбора и хранения, либо может вообще вычисляться на основе собранных метрик.
Триггер
Элементы созданы и собирают данные, много данных. Понятно, что следить за ними самостоятельно нет никакой возможности. Но мы должны как-то реагировать на их изменения, желательно без непосредственного участия человека. Для оценки собираемых данных предназначены триггеры (Trigger), триггер содержит выражение, представляющее некоторое пороговое значение с которым постоянно сравниваются поступающие данные. При выходе за указанное пороговое значение триггер срабатывает и переходит в состояние проблема, давая понять, что что-то произошло и может потребовать нашего внимания.
Что это может быть? Самое простое - выход контролируемого параметра за некие контрольные пределы, например, загрузка CPU. Ниже приведен именно такой триггер, который анализирует среднюю нагрузку на процессор за последние пять минут и сработает в случае превышения порогового значения. Обратите внимание, что пороговое значение задано в виде переменной, что дает возможность переопределить ее на уровне узла сети.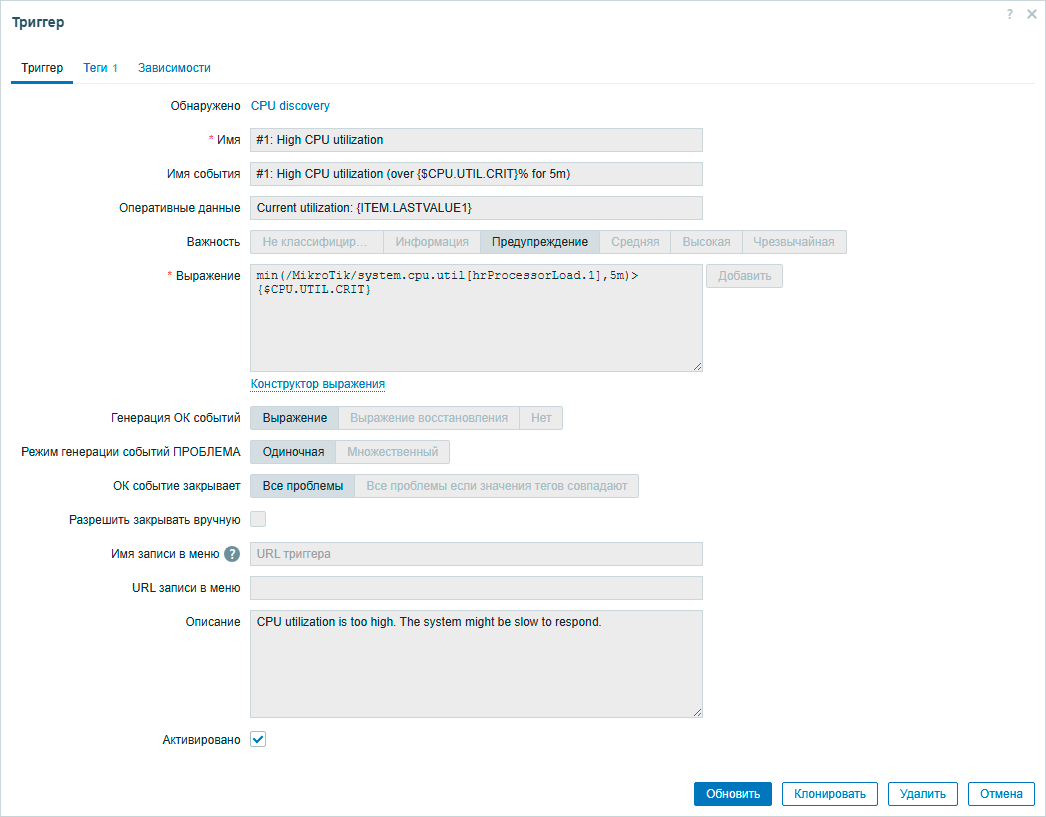
У каждого триггера есть степень важности, в нашем случае превышение нагрузки на процессор является Предупреждением, но мы можем создать несколько триггеров с разными пороговыми значениями и разной степенью важности. Это позволяет как настроить разные действия, так и фильтровать журнал текущих проблем, отображая только актуальные.
Что будет, если поступающие данные вновь вернутся в допустимый диапазон? Это описано в настройке Генерация ОК событий, в нашем случае там стоит значение Выражение, это означает что срабатывание триггера и обратный переход его в состояние ОК определяется одним и тем же выражением. Т.е. как только нагрузка в течении последних 5 минут не будет превышать пороговое значение триггер сам переключится обратно. Однако мы можем задать отдельное выражение для генерации этого события, например, триггер будет возвращаться в состояние ОК только тогда, когда пороговое значение не будет превышено в течении, скажем, получаса.
Такой подход позволяет избегать многократного срабатывания триггера, если нагрузка носит периодический пиковый характер в течении продолжительного времени и один раз сработавший триггер будет находиться в состоянии проблема все время пока нагрузка не придет в норму.
Каждое срабатывание триггера генерирует событие типа Проблема, мы можем настроить однократный режим, когда событие создается при первом срабатывании триггера и более не повторяется до его перехода в состояние ОК, либо можно генерировать проблему при каждом срабатывании триггера, вне зависимости от предыдущего состояния. Так в нашем случае при поступлении данных раз в минуту и продолжающейся нагрузке на процессор вы будете получать новое срабатывание и новую проблему каждую минуту.
Зачем это может быть нужно? Для проблем с уровнем Чрезвычайная, когда нужно всеми способами обратить на нее внимание ответственных лиц.
Некоторые триггеры можно разрешить закрывать вручную. Обычно это события уровня информация, когда просто нужно уведомить о чем-то администратора и получить от него подтверждение, что он информацию принял и отреагировал. Например, это триггер об изменении версии прошивки устройства.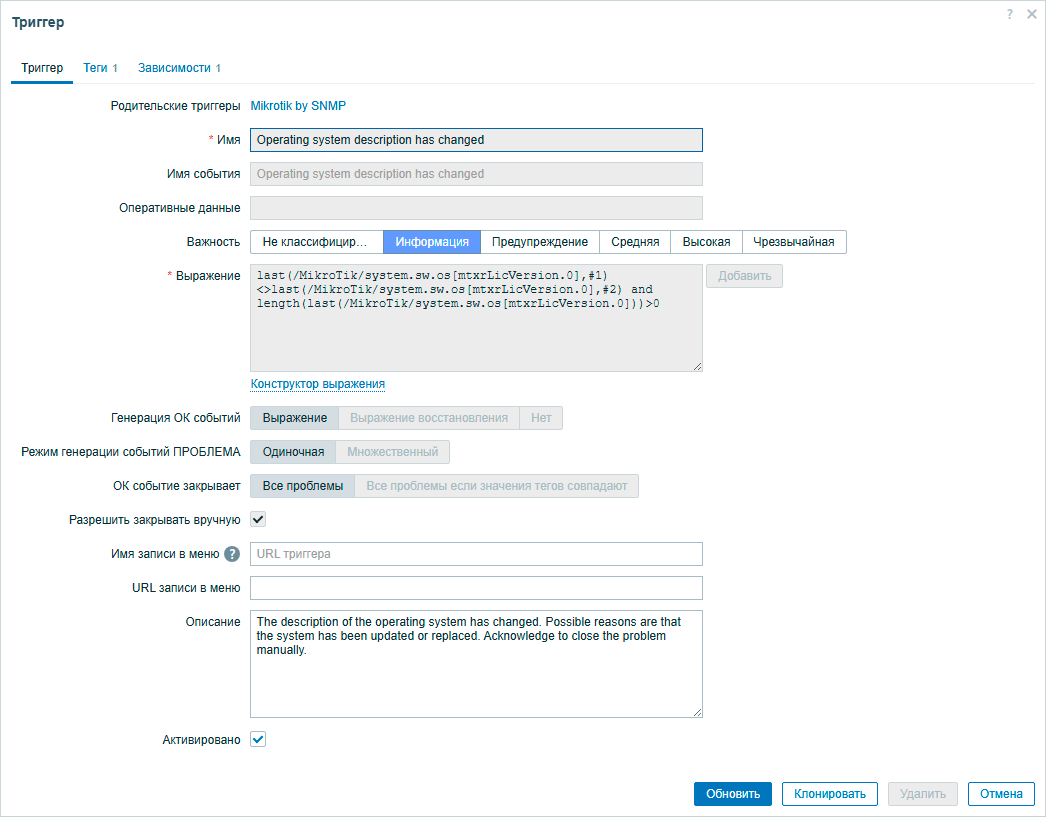
Данный триггер может помочь вам проконтролировать обновление прошивок парка роутеров в пакетном режиме. Все обновились, все отчитались, посмотрели и закрыли проблему вручную. А что будет, если администратор ее проигнорирует? Она провисит ровно час, через час (период опроса) первое значение прошивки будет равно второму и триггер автоматически перейдет в состояние ОК закрыв проблему.
Однако вы всегда сможете проконтролировать это событие в истории проблем. Но мозолить глаза и наводить суету оно вам больше не будет. И таких триггеров довольно много, которые генерируют событие на короткое время, а потом снова переходят в состояние ОК. Скажем, триггер на перезагрузку узла, оно создает проблему ровно на 10 минут, после чего снова переходит в состояние ОК. Если никто не отреагировал, то, скорее всего, так оно и надо.
Действия
Каждое срабатывание триггера порождает событие (Event) и для реакции на событие мы можем использовать действие (Action). Одним из штатных действий является оповещение. Если мы его откроем, то увидим, что условия срабатывания у него отсутствуют, т.е. работать оно будет по любому событию не разделяя их по важности.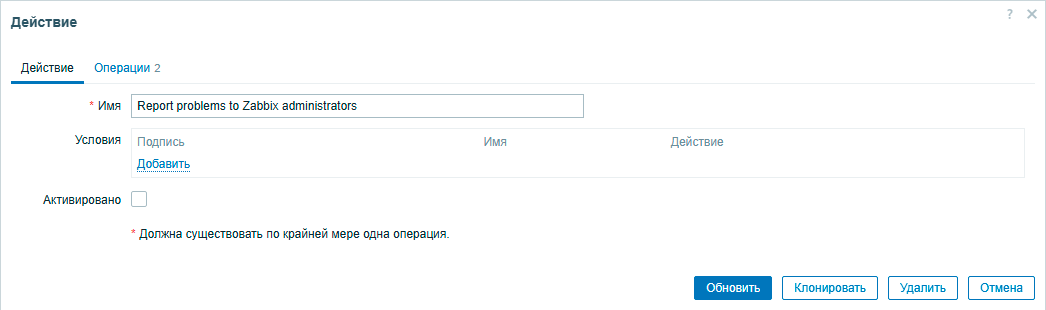
Но сейчас это не важно, после срабатывания действия оно выполнит указанные в нем операции. В нашем случае оповестит всех администраторов всеми доступными способами.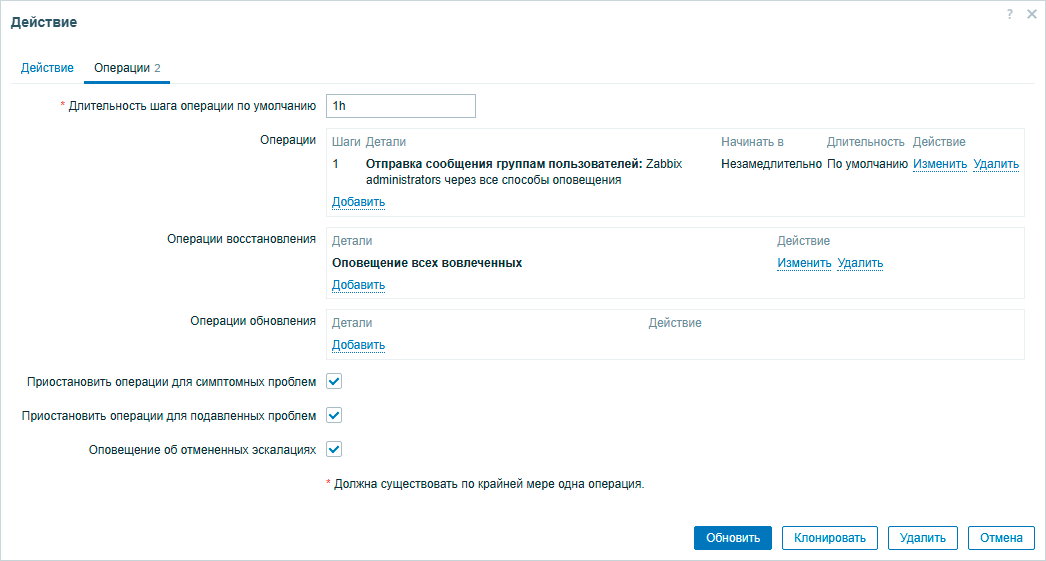
Кроме действия по срабатыванию триггера мы можем настроить действия по его восстановлению и обновлению. Так, если контролируемая метрика снова пришла в норму, то мы можем уведомить об этом всех причастных чтобы они перестали нервничать и занялись своими повседневными делами. Операции обновления позволяют отреагировать на то, что кто-то занялся проблемой и внес какие-либо изменения в ее статус: подтвердил, закрыл вручную или изменил степень важности. Об этом тоже можно автоматически уведомить коллег чтобы не получилось так, что сразу несколько сотрудников одновременно решают одну и ту же проблему.
Но действия это не только уведомления, Zabbix умеет выполнять на узлах сети удаленные команды. Часто для реакции на событие вовсе не обязательно дергать администратора, особенно если для его устранения требуются простые действия. Скажем поступил сигнал, что свободное место на пользовательском ПК заканчивается. В этому случае мы можем удаленно запустить очистку диска, что в подавляющем большинстве случаев проблему решит.
А если не решит? В этом случае можем использовать эскалацию, под этим словом подразумевается добавление в операции дополнительных шагов. В нашем случае после запуска очистки диска мы можем подождать 15 минут и если проблема не разрешилась, то уведомить администратора.
Данную возможность трудно переоценить, так как она позволяет создавать развернутые сценарии, например:
Как видим, при помощи действий мы можем комбинировать как уведомления, так и активные действия направленные на решение проблемы если никакой реакции от ответственных лиц не последует.
Шаблоны
Элементы данных, триггеры - все это хорошо, но даже на одном узле сети их может быть множество, не будем же мы их добавлять руками? Конечно же не будем, для этого у нас существуют шаблоны (Template), каждый шаблон содержит элементы данных и связанные с ними триггеры для определенного применения. Так, если у вас Windows система, то вы берете шаблон для Windows, Linuх- для Linux и применяете его к узлу сети.
Можно применить несколько шаблонов, допустим у нас есть узел Proxmox и мы применяем к нему шаблоны Linux by Zabbix agent и Proxmox VE by HTTP, каждый из которых собирает собственный набор данных и содержит собственные триггеры. Но это еще не все, кроме элементов данных и триггеров шаблоны могут содержать предварительно настроенные графики и панели, что облегчает визуальное восприятие собираемой информации.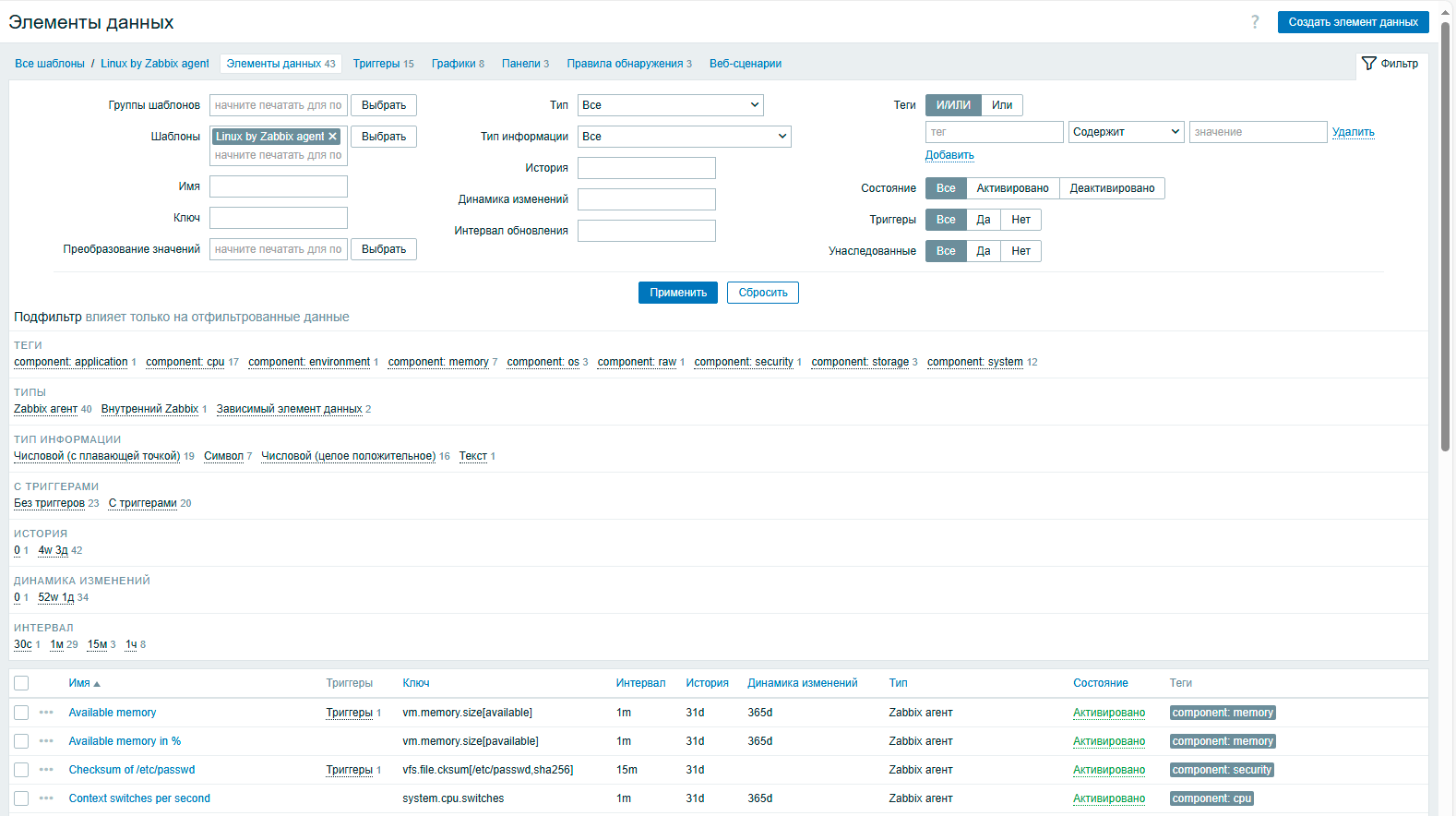
Отдельное внимание следует уделить правилам обнаружения. Скажем, подключая некоторый узел мы можем быть уверены, что там есть процессор и память. А вот если ли накопители, какие и сколько, какие на них файловые системы, сколько и каких сетевых адаптеров - это вопросы не имеющие однозначного ответа. Правила обнаружения позволяют автоматически получать информацию о подобных сущностях и добавлять их в мониторинг. Добавили в систему новый диск? Никаких проблем, автоматически появится в мониторинге.
Шаблоны значительно облегчают работу администратора Zabbix. Для большинства популярных решений они идут в комплекте поставки, если нужного шаблона нет, то вы можете скачать готовый с сайта производителя решения или магазина Zabbix и добавить его в систему мониторинга. Ну а если очень хочется чего-то необычного, то вы всегда можете создать шаблон вручную.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:
![]()
Или подпишись на наш Телеграм-канал: ![]()