Резервное копирование и восстановление баз данных PostgreSQL при помощи pg_dump на платформе Linux
Резервное копирование - одна из важнейших задач системного администратора. Хорошо если копии вам никогда не пригодятся, но они должны быть. Сегодня мы рассмотрим некоторые аспекты резервного копирования популярной СУБД PostgreSQL, в частности при ее применении совместно с 1С:Предприятие. Продолжим с утилиты pg_dump - самого простого и понятного способа, который, кстати, может использоваться не только для резервного копирования, но и для переноса баз между различными серверами. Теперь уже на платформе Linux.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Как и любой иной способ использование pg_dump для копирования имеет свои плюсы и минусы. К основному минусу можно отнести то, что создаваемый дамп является срезом базы данных на некоторый момент времени и позволяет откатиться только на это состояние. Восстановление на произвольный момент времени невозможно.
Иные способы, позволяющие такое восстановление, работают на уровне инстанса и позволяют восстановить сразу весь кластер, т.е. все базы. Поэтому рекомендации по продуктовому применению PostgreSQL предусматривают основную схему: 1 база - 1 инстанс, что для небольших внедрений может быть избыточно как по ресурсам, так и по накладным расходам на администрирование.
В тоже время pg_dump работает на уровне базы данных и позволяет копировать и откатывать именно определенную базу, не затрагивая соседей по кластеру. Это несомненный плюс.
Также pg_dump может использоваться для переноса баз данных, она кроссплатформенна и кроссверсионна, т.е. позволяет переносить базы между разными платформами и разными версиями PostgreSQL. При этом следует помнить, что версии PostgreSQL совместимы снизу вверх, совместимость сверху вниз не поддерживается, либо поддерживается на ограниченное число версий. Т.е. вы всегда сможете загрузить дамп из PostgreSQL 9.6 в PostgreSQL 15, но не наоборот.
Подготовка сервера
Для удобства работы с утилитами Postgres они должны быть доступны по стандартным путям PATH, обычно так оно и происходит, но не будет лишним проверить. Для этого выполним команду:
1whereis psql
Если мы получим следующий ответ, то все в порядке:
1psql: /usr/bin/psql /usr/share/man/man1/psql.1.gz
Нужный бинарный файл (точнее ссылка на него) находится в стандартном каталоге для исполняемых файлов /usr/bin. В противном случае нам нужно найти место установки вашего экземпляра PostgreSQL, в частности директории bin, например, PostgreSQL 15 от Postgres PRO устанавливается по пути /opt/pgpro/1c-15. Обнаружив место установки просто запустим утилиту pw-wrapper, которая самостоятельно сделает все необходимые ссылки.
1/opt/pgpro/1c-15/bin/pg-wrapper links update
После того, как разобрались с путями следует проверить права доступа, для этого перейдем в рабочий каталог кластера, его стандартное расположение /var/lib/postgresql/15/main, где 15 - версия сервера. Версия от Postgres PRO устанавливается по другому пути: /var/lib/pgpro/1c-15/data. Так или иначе нас интересует файл pg_hba.conf который содержит правила аутентификации на сервере. Его содержимое примерно следующее:
1# TYPE DATABASE USER ADDRESS METHOD
2
3# "local" is for Unix domain socket connections only
4local all all peer
5# IPv4 local connections:
6host all all 127.0.0.1/32 md5
Первая строка с типом local отвечает за подключение через Unix-сокет, разрешает подключение к любой базе данных (all), любым пользователем (all) с использованием механизмов аутентификации операционной системы (peer).
Строка с типом host отвечает за подключения через TCP/IP, также к любой базе, любым пользователем с адреса 127.0.0.1/32 при помощи пароля (md5). Таким образом мы можем использовать в строке подключения только 127.0.0.1 или localhost, если мы там укажем FQDN или IP-адрес узла, то соединение будет отвергнуто, также Postgres не будет принимать соединения из локальной сети.
Чтобы изменить это поведение добавьте в файл еще одну строку:
1host all all 192.168.54.32/32 md5
Где 192.168.54.32 - IP-адрес вашего компьютера, после чего в строке подключения можно использовать как этот адрес, так и имя ПК.
Если вы хотите подключаться к серверу СУБД из локальной сети добавьте:
1host all all 192.168.54.0/24 md5
В данном случае мы указали в правиле полную подсеть с маской 255.255.255.0, которая иначе записывается как /24.
Также вместо адресов можно использовать зарезервированные слова:
- samehost - любые адреса данного ПК
- samenet - любые адреса сетей, непосредственно подключенных к данному узлу
Например:
1host all all samehost md5
В современных системах можно использовать более стойкую криптографию для хеширования пароля, для этого просто замените в файле md5 на scram-sha-256:
1host all all samehost scram-sha-256
После чего следует перезапустить службу сервера, для обычного экземпляра это можно сделать командой:
1systemctl restart postgresql
Для Postgres PRO имя службы будет другим:
1systemctl restart postgrespro-1c-15
Обратите внимание, что оно содержим имя версии.
Следующий момент - пароль пользователя, под которым мы будем работать с кластером PostgreSQL, обычно это суперпользователь СУБД с именем postgres, но может быть и другой пользователь. Если изначально пароль не был установлен, то соединение возможно только через Unix-сокет, поэтому войдем под пользователем системы postgres и установим пароль пользователю СУБД postgres (или любому другому):
1su postgres
2
3psql
4ALTER USER postgres WITH PASSWORD 'MyPa$$word';
5\q
6
7exit
Чтобы постоянно не вводить пароль создадим специальный файл в домашней директории пользователя, который будет хранить данные для аутентификации. Для этого используем редактор nano, если вам больше нравится редактор mc, то замените nano на mcedit.
1nano ~/.pgpass
И внестие в него следующие строки:
1#имя_узла:порт:база_данных:имя_пользователя:пароль
2localhost:*:*:postgres:MyPa$$Word_1
Сохраним изменения и установим на него нужный набор прав, который исключит доступ к содержимому файла для всех, кроме владельца:
1chmod 600 ~/.pgpass
Также не забываем, что в Linux данный файл применяется только для того пользователя, в домашней директории которого он находится, если вы планируете производить резервное копирование при помощи скриптов, которые будут запускаться от суперпользователя root, то следует создать указанный файл и для него. Для этого нужно повысить права до суперпользователя, в Ubuntu это можно сделать так:
1sudo -s
В Debian, где sudo может быть не установлен, используйте:
1su -
После чего повторите указанные выше действия.
Создание резервной копии базы данных
Утилита pg_dump умеет создавать копии в разных форматах, каждый из которых имеет свои достоинства и недостатки.
- plain - выгрузка в текстовом SQL формате. Наиболее универсальна, а при необходимости позволяет вручную откорректировать дамп или выполнить частичную загрузку или восстановление, например отдельной таблицы. Не сжимается, имеет большой размер.
- custom - собственный формат pg_dump, предусматривает сжатие данных и возможность многопоточной загрузки, выгружается всегда однопоточно
- directory - выгрузка в виде директории, на каждую таблицу выгружается отдельный сжатый файл, позволяет многопоточную выгрузку и загрузку
- tar - представляет, по сути, выгрузку в виде директории, но упакованной в tar-архив, сжатие не предусмотрено, поэтому размер выгрузки будет больше, чем у директории, однопоточен
Таким образом, наиболее удобными с практической точки зрения является формат custom, либо directory - если вам требуется многопоточная выгрузка. При переносе между разными системами предпочтительно использовать plain, так как он представляет набор SQL команд и может быть легко отредактирован вручную.
Итак приступим. Прежде всего следует узнать какие базы данных есть на нашем сервере и как они называются, для этого выполним:
1psql -h localhost -U postgres -l
В выводе мы увидим список баз и их параметры: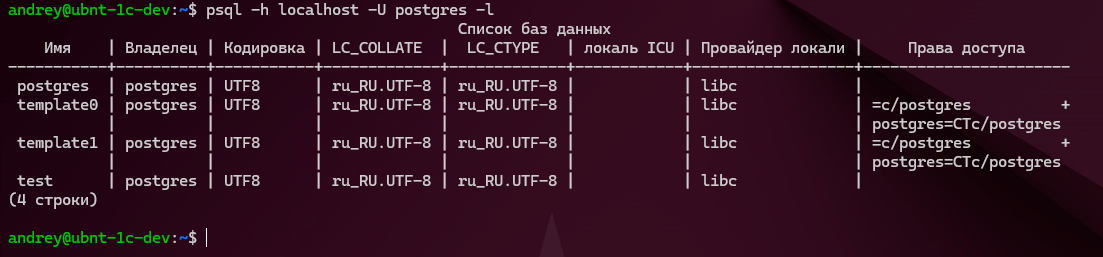
В нашем случае мы будем бекапить базу данных test и местом хранения резервных копий определим /mnt/backup. Начнем с текстового формата, он используется по умолчанию и отдельно указывать его не нужно:
1pg_dump -h localhost -U postgres -f /mnt/backup/test.sql test
Общий синтаксис команды такой: сначала указываем все используемые ключи, первый аргумент без ключа считается именем базы данных, и оно должно быть последним в команде. Указывать ключи после имени базы не следует. В команде мы использовали ключи:
- -h сервер - указывает имя или адрес компьютера, на котором работает сервер СУБД
- -U имя_пользователя - имя пользователя, под которым производится подключение
- -f файл - файл, в который производится выгрузка
Также ниже мы будем использовать ключи:
- -F формат - формат выгрузки
- -j число_заданий - количество потоков
С полным перечнем ключей можно ознакомиться в официальной документации.
Очень часто можно встретить такой вариант команды:
1pg_dump -h localhost -U postgres test > /mnt/backup/test.sql
Мы неоднократно сталкивались с тем, что выгруженные через перенаправление копии внешне выглядели вполне нормально, в том числе и копии в текстовом формате, но при восстановлении отказывались загружаться. Это происходит не всегда и не везде, преимущественно на платформе Windows, но для исключения подобных ситуаций перенаправление для создания резервных копий postgreSQL лучше не использовать.
Важно! Не используйте перенаправление для выгрузки и загрузки резервных копий!
Теперь создадим выгрузку в формате custom:
1pg_dump -h localhost -U postgres -Fc -f /mnt/backup/test.dump test
Здесь у нас добавился еще один ключ, указывающий на формат выгрузки, если вы хотите выгрузить в формате tar, просто замените -Fc на -Ft.
И, наконец, в формате директории:
1pg_dump -h localhost -U postgres -Fd -f /mnt/backup/test_dir -j 4 test
Для данного формата у нас появился еще один ключ, указывающий число потоков выгрузки. Число потоков не должно превышать количество ядер процессора, но не все так просто: pg_dump спокойно нагрузит каждый поток, создав 100% загрузку ядер процессора, но сможет ли его принять устройство хранения? Может получиться так, что скорость записи на накопитель окажется бутылочным горлышком и вместо ускорения вы получите замедление как выгрузки дампа, так и всей системы вообще.
Поэтому начните с небольшого количества, двух или четырех потоков, оцените нагрузку на систему и остановитесь на некотором оптимальном значении, это особенно важно, если на сервере в момент выгрузки будут работать пользователи. Нам ведь совершенно ни к чему чтобы они каждый час жаловались на тормоза.
Еще одна тонкость, что будет если указанный файл выгрузки существует? Форматы, custom и tar молча перезапишут его. При выгрузке в формате directory вы получите сообщение, что целевая директория не пуста и выгрузка выполнена не будет. Это следует учитывать при написании скриптов, потому как при ошибке вы либо останетесь без старых копий, либо не будут создаваться новые. Хотя визуально все будет нормально.
Особенно легко ошибиться в случае с directory, если вы используете для выгрузки одну и ту же директорию, потом дополнительно архивируете ее и отправляете на устройство хранения. В этом случае вы будете архивировать одну и ту же старую копию. Поэтому директорию выгрузки надо всегда очищать или удалять.
Восстановление базы данных из резервной копии
Начнем с того, что восстановить базу данных PostgreSQL можно только в новую, пустую базу. Если мы хотим восстановить ее в существующую, то ее придется сначала удалить, а потом создать новую с таким же именем. Исключение - формат plain, это просто набор SQL-команд, которые мы можем выполнить на рабочей базе, выборочно туда что-то подгрузив. Но это требует определенных знаний и квалификации, что выходит за рамки нашей статьи.
Итак, прежде всего удалим старую базу:
1dropdb -h localhost -U postgres -i test
В приведенной команде мы использовали ключ**-i** который запросит интерактивное подтверждение действия:
1База данных "test" будет удалена навсегда.
2Продолжить? (y/n)
Почему мы это сделали и советуем вам поступать также? Как показывает практика, данные команды часто вводятся методом копирования, неважно откуда, из статьи, документации, собственных записей, истории команд. В этом случае интерактивный запрос послужит предохранителем, который позволит остановиться и задуматься что вы делаете.
А теперь создадим новую:
1createdb -h localhost -U postgres -T template0 test
Ключ -T указывает использовать при создании базы полностью пустой шаблон template0. Если вы хотите выполнить восстановление в отдельную новую базу, то просто создайте ее приведенной выше командой.
Начнем восстановление с формата plain, так как это не дамп, а набор SQL команд, то для их исполнения мы будем использовать утилиту psql:
1psql -h localhost -U postgres -d test /mnt/backup/test.sql
Формат команды здесь такой же, сначала ключи, потом файл или директория, из которой идет восстановление. Ключ -d указывает имя базы данных, в которую мы загружаем выгрузку.
Для остальных форматов следует использовать утилиту pg_restore, например восстановим дамп формата custom, в два потока:
1pg_restore -h localhost -U postgres -d test -j 2 /mnt/backup/test.dump
Синтаксис тот же самый, просто указываем базу и файл, с форматом утилита разберется самостоятельно. Если же вы попытаетесь подсунуть ей формат plain, то утилита откажется делать загрузку и любезно посоветует вам использовать для этого psql.
Что касается выбора количества потоков, то исходим из тех же соображений: один поток - одно ядро и обязательно тестируем, чтобы производительность диска не стала узким горлышком. Если вы выполняете восстановление в рабочее время, то учтите также влияние на работу пользователей, чтобы не вышло что вы запустили восстановление, а у всех остальных все стало.
При восстановлении из формата directory вместо файла укажите путь к папке:
1pg_restore -h localhost -U postgres -d test -j 2 /mnt/backup/test_dir
Напоминаем, что формат tar многопоточную загрузку не поддерживает, но вы можете его распаковать и загрузить многопоточно в формате directory.
Также есть способ несколько упростить себе жизнь, чтобы не удалять и не создавать заново базу данных мы можем выполнить:
1pg_restore -h localhost -U postgres -d postgres -C -c /mnt/backup/test.dump
Ключи -C -c предписывают перед загрузкой удалить и создать заново базу имя которой записано в дампе, в ключе -d при этом потребуется указать любую существующую базу, обычно указывается стандартная postgres. В результате выполнения данной команды вы можете получать некоторые безвредные сообщения об ошибках.
Однако использовать эту команду следует очень осторожно и только на том сервере, откуда был сделан дамп. Также убедитесь, что вы взяли именно тот дамп, что надо. Но мы не рекомендуем так делать, особенно на продуктовых серверах, лучше осознанно удалите базу руками.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:
![]()
Или подпишись на наш Телеграм-канал: ![]()