Ubuntu Server. Администрирование программного RAID
В продолжение нашего материала о программном RAID в Ubuntu Server мы рассмотрим основные задачи администрирования такого массива. Ведь недостаточно только создать RAID, нужно постоянно контролировать его состояние и своевременно заменять диски в случае их отказа. Об этом и пойдет речь в данной статье.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Сразу хотим обратить ваше внимание: создание RAID массива страхует от аппаратного отказа дисков и никоим образом не отменяет резервные копии. Поэтому перед любыми операциями с RAID обязательно сделайте резервное копирование всех ваших данных. К сожалению, ошибочная замена не того диска в массиве или перезеркаливание чистого диска на диск с данными - это не админский фольклор, а реальные случаи, причем имеющие тенденцию регулярно повторяться.
Поэтому, сразу после того, как вы создали массив и успешно установили туда систему, не поленитесь проделать ряд организационных мероприятий, которые позволят избежать досадных ошибок в будущем. Запишите в отдельный журнал серийные номера жестких дисков, порт подключения на материнской плате и наименование в системе каждого из них, а также снабдите каждый диск наклейкой с аналогичной информацией. Это избавит вас, в будущем, от вопросов: а какой из них sda?
Также следует составить план замены жестких дисков в массиве и обеспечить достаточный запас новых дисков для обеспечения бесперебойной работы предприятия. Сейчас мне могут возразить, мол такой подход применим только для крупных предприятий, небольшие фирмы не могут себе позволить держать запас дисков, тем более диски выходят из строя не так уж и часто. Это распространенное заблуждение и чаще всего в этом убеждаются только после потери данных. Поэтому сделаем небольшое теоретическое отступление.
Как правильно рассчитать вероятность отказа? Простая на первый взгляд задача оказывается не такой уж и простой, все дело в неправильном понимании некоторых терминов. Чаще всего путаницу вносит такой показатель как наработка на отказ (MTBF), например у 500 Gb Western Digital RE4 (WD5003ABYX) этот показатель составляет 1,2 млн. часов, а у массовой модели 500 Гб Caviar Blue (WD5000AAKS) - 650 тыс. часов. На первый взгляд какие-то безумные цифры, глядя на которые можно предположить, что диски должны работать вечно. Однако это не так. Под наработкой на отказ подразумевается среднее время до отказа одного диска из всей партии в течении заявленного гарантийного срока. Что это значит? Что в течении трех лет заявленной гарантии вы можете ожидать отказ для каждого 46-го диска из партии (для RE4).
Однако нам более интересно, какая вероятность отказа для отдельного диска, так как все купленные нами диски могут оказаться как 46-ми (т.е. могут отказать), так и не оказаться ими (проработают без отказа). Для этого рассчитаем такой параметр, как ежегодная вероятность отказов (AFR), который рассчитывается по формуле:
1AFR = 1 - exp(-8750/MTBF)
Для одного диска серии RE получим вероятность отказа 0,7%, а для серии Blue - 1,3%, казалось бы цифры небольшие, но не будем забывать, что это вероятность отказа одного диска, для нескольких дисков формула будет иметь вид:
1AFR = 1 - exp(-8750*n/MTBF)
где n - количество дисков, так для 2 и 4 дисков (RE4 / Blue) получим 1,4% / 2,7% и 2,9% / 5,2% соответственно.
За три года, если считать что вероятность отказа в течении этого времени постоянна (на самом деле это не так) получим для 4 дисков величину 8,7% / 15,6% для разных серий. Как видим, для настольной серии значение довольно велико и не может быть проигнорировано. Вероятность одновременного отказа двух дисков составит 0,8% для северной серии и 2,4% для массовой "синей". Помня, что в большинстве случаев одновременный отказ двух дисков приводит к полному разрушению массива, то это тоже весьма немаленькая цифра. Под одновременным отказом следует понимать не одновременный выход из строя, а последовательный отказ в течении довольно малого промежутка времени (несколько дней - неделя), и не имея под рукой резервного диска можно не всегда успеть приобрести новый диск для замены отказавшего.
Наш расчет справедлив для одинаковой вероятности выхода из строя в течении гарантийного срока (3 года), реально это показатель имеет тенденцию к увеличению, что подтверждают различные исследования, в своей практике мы применяем повышающие коэффициенты 1,25 для второго и 1,5 для третьего годов эксплуатации. С учетом этого получим вероятность отказа для 4 дисков в течении трех лет для RE серии - 10,8% (каждый десятый диск) и для Blue серии - 19,7% (каждый пятый диск). Вероятность одновременного отказа двух дисков - 1,2% и 3,9% соответственно.
Какие выводы можно сделать? Во первых, постарайтесь не использовать недорогие диски массовых серий, либо уменьшайте срок их эксплуатации до получения приемлемых значений надежности (для серии Blue таким сроком можно считать 2 года), во вторых составьте план замены выработавших свой ресурс дисков, не дожидаясь их выхода из строя и не используйте диски с истекшим сроком гарантии.
Также всегда имейте под рукой определенное количество исправных дисков, достаточное для того, чтобы оперативно заменить вышедшие из строя. Это число следует рассчитывать исходя из расчетной вероятности отказов и требований к надежности системы хранения данных. Не забывайте включать эти диски в план замены, чтобы они не залеживались до конца гарантийного срока, на наш взгляд оптимально держать диски в резерве год, затем приобретать туда новые, а эти использовать для плановых замен. Для ответственных систем мы рекомендуем использовать диски горячей замены (тем более штатные возможности Ubuntu это позволяют), которые будут автоматически использованы при отказе одного из дисков.
Если кто-то еще считает, что подобные мероприятия все еще слишком дороги, спросите себя и руководство, соизмерима ли стоимость двух-трех дисков с возможным ущербом от простоя или потери данных по причине их выхода из строя, вероятность подобного события нетрудно рассчитать по формулам выше.
Перейдем от теории к практике. В нашем распоряжении имеется тестовый сервер на Ubuntu Server 10.04.3 LTS установленная на программный RAID1 (зеркало). Для администрирования массива используется утилита mdadm, которая уже установлена в системе. Рассмотрим типовые ситуации и действия администратора в них.
Массив перешел в состояние inactive
Такая ситуация возникает при выходе из строя нескольких дисков или при иных аппаратных сбоях. Проявляется это в недоступности массива, если массив загрузочный, то загрузка с него будет невозможна. В первую очередь проверяем состояние дисков, показания S.M.A.R.T, делаем тест поверхности и, если все нормально или почти все нормально (найдены и исправлены бэд-блоки и планируется замена диска), то заново собираем массив командой:
1mdadm /dev/md0 --assemble --scan
В случае с загрузочным массивом нужно будет загрузиться с установочного диска в режим восстановления. Бывает массив переходит в данное состояние при полностью исправных дисках, например при сбоях в электропитании, но в любом случае такая ситуация требует проведения полной проверки дисков и обстоятельств произошедшего.
Замена диска при некритическом отказе или плановая замена
Прежде всего выясняем, какой именно диск нам необходимо заменить, вот здесь и придет на помощь созданный ранее журнал и наклейки на дисках. Затем помечаем его как сбойный:
1sudo mdadm /dev/md0 --fail /dev/sdb1
В отличии от команды --remove, которая удаляет диск из массива, команда**--fail** позволяет отключить диск не останавливая работу массива, на загрузочных массивах это единственная возможность отключить диск. Ниже показана попытка отключить сбойный диск у загрузочного массива и прекрасно видна разница между этими двумя командами: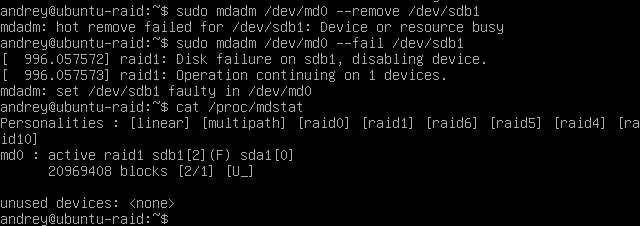
Затем выключаем сервер и физически меняем диск. Загружаемся, теперь нужно просмотреть список всех подключенных дисковых устройств, чтобы выяснить как наш новый диск определился в системе:
1sudo fdisk -l
Из вывода команды определяем, что новый диск имеет имя sdb и не содержит разделов.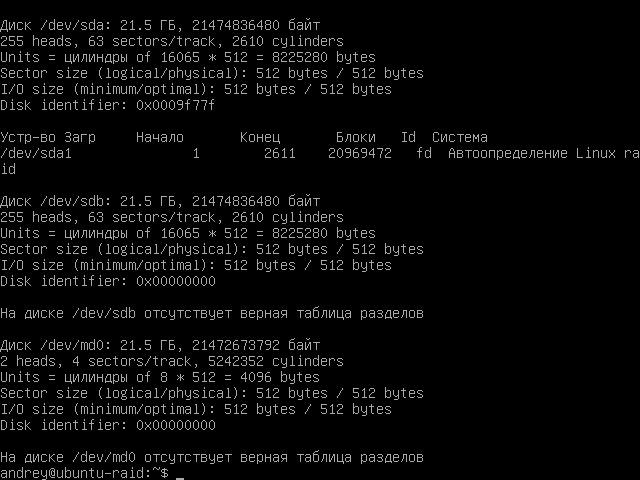
Так как единицей программного массива является не диск, а раздел, мы не можем подключить к массиву чистый диск и нужно создать на нем аналогичный раздел. Однако эта задача не так проста, как кажется, отклонение в размерах раздела даже на 1 сектор сделает невозможным добавление его в массив. Поэтому самым простым решением будет скопировать разметку (со всем содержимым) с исправного диска:
1sudo dd if=/dev/sda of=/dev/sdb bs=1M
После чего перезагружаемся и добавляем раздел в массив командой:
1sudo mdadm /dev/md0 --add /dev/sdb1
Теперь если выполнить
1cat /proc/mdstat
мы увидим процесс ресинхронизации массива: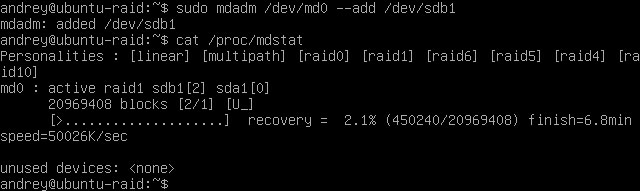
Замена диска при критическом отказе
Под критическим отказом понимается ситуация, когда жесткий диск полностью вышел из строя. В этом случае определяем название отказавшего диска при помощи mdstat и производим его замену, далее порядок действий полностью аналогичен предыдущему пункту.
Добавление резервного диска и расширение массива
Кроме замены дисков перед администратором так-же встают задачи расширения массива (для тех уровней, которые это допускают) и добавление новых дисков горячей замены. Для добавления нового диска на нем также надо создать копию раздела с исправного диска массива и добавить его командой:
1sudo mdadm /dev/md0 --add /dev/sdс1
Добавленные в исправный массив диски считаются резервными и будут автоматически использованы при отказе одного из основных. Резервные диски (hot spare) обозначаются в выводе mdstat как S, отказавшие - F.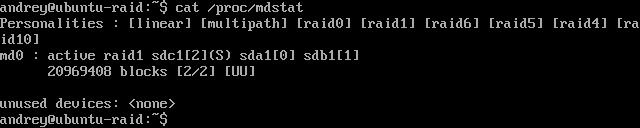
Для проверки пометим один из дисков сбойным. Как видим резервный диск был автоматически добавлен в массив и началась ресинхронизация.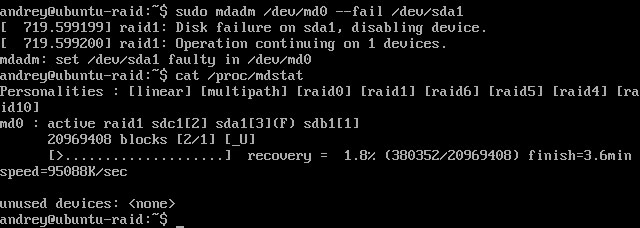
Резервные диски также можно использовать для расширения массива, для этого используется команда --grow, в качестве опции которой передается количество дисков в расширенном массиве. Например мы хотим расширить RAID5 массив (md2) из трех дисков (sda1, sdb1, sdc1) и одного резервного диска (sdd1), на четыре диска (используя для этого резервный). Это можно сделать командой:
1sudo mdadm /dev/md2 --grow --raid-devices=4
Расширение будет произведено без отключения массива и абсолютно прозрачно для пользователя. Однако перед любыми подобными операциями следует обязательно создать резервные копии, если позволяют ресурсы, оптимально скопировать каждый из дисков массива на резервные командой dd, если что-то пойдет не так, достаточно будет просто заменить диски.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:
![]()
Или подпишись на наш Телеграм-канал: ![]()