Linux - начинающим. Что такое Load Average и какую информацию он несет
С необходимостью правильно оценить нагрузку на систему сталкивается каждый системный администратор. Если говорить о Linux-системах, то одним из основных терминов, с которым придется столкнуться начинающему администратору окажется Load Average (средняя загрузка). Однако, если говорить о русскоязычном сегменте сети интернет, описание данного параметра сводится к общим малозначащим фразам, в то время как за этими простыми цифрами кроется глубокий пласт информации о работе системы.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Если обратиться к популярным источникам (Википедия), то можно найти примерно следующее:
Средняя загрузка - среднее значение загрузки системы за некоторый период времени, как правило, отображается в виде трёх значений, которые представляют собой усредненные величины за последние 1, 5 и 15 минут, чем ниже, тем лучше. В UNIX это среднее значение вычислительной работы, которую выполняет система.
После прочтения данного абзаца никаких новых знаний, кроме того, что масло таки масляное (средняя загрузка -- среднее значение загрузки) не возникает и понимания ситуации не прибавляется. Чем ниже, тем лучше, но насколько ниже и относительно чего.
Посмотреть текущую загрузку системы можно командной
1uptime
Также ее значения выводят утилиты top и htop, а также множество других инструментов. В ответ мы получим что-то вроде:
1load average: 0,12, 0,10, 0,03
Много это или мало? Хорошо или плохо? Давайте разбираться.
Чтобы понять, что такое загрузка системы следует обратиться к логике работы центрального процессора. Вне зависимости от того, мощный у вас процессор или слабый, многоядерный или нет, он выполняет некий программный код для некоторых процессов. Если процесс один, то вопросов нет, а вот когда их несколько? Надо как-то распределять ресурсы между ними и, желательно, равномерно, чтобы один процесс, "дорвавшись" до CPU, не оставил без вычислений другие.
Здесь можно провести аналогию, когда несколько игроков хотят поиграть на одной приставке. Что обычно делают в таких случаях? Договариваются о времени, скажем каждый играет по 15 минут, затем дает поиграть другому.
Процессор поступает аналогичным образом. Каждому нуждающемуся в вычислениях процессу выделяется некий промежуток времени, который зависит от типа процессора и системы, если говорить о современных процессорах Intel, то это значение обычно составляет 10 мс и называется тиком. Каждый тик процессорное время отдается какому-то одному процессу в порядке очереди, но если процесс имеет повышенный или пониженный приоритет, то он, соответственно получит большее или меньшее количество тиков.
Количество использованных тиков, в первом приближении, и представляет загрузку системы. В Linux для оценки загрузки используется интервал в 500 тиков (5 секунд), при этом учитываются как работающие процессы (использованные тики), так и ожидающие (которым не хватило тика, либо они не смогли его использовать, ожидая завершения иной операции).
Если мы используем все тики за указанный промежуток времени и у нас не будет ожидающих сводного тика процессов, то мы получим загрузку процессора на 100% или load average (LA) равное 1.
Давайте рассмотрим следующую схему:
Для простоты мы будем использовать в расчетах более короткий интервал - 9 тиков. На схеме слева мы видим, что процессорные ресурсы сначала понадобились системе, затем браузеру и файловому менеджеру, потом активности в системе не было, затем еще один тик взял файловый менеджер и еще два браузер, последние два тика также не понадобились никому. Несложные расчеты показывают, что мы использовали 67% процессорного времени или load average системы составил 0,67.
Справа показана ситуация, когда каждый тик был занят своим процессом, но некоторые процессы так и не получили своего тика или не смогли получить, например, ждали окончания операции ввода-вывода. В таком случае загрузка процессора составит все те же 100%, но load average вырастет до 1,33, указывая на наличие очереди.
Чтобы лучше понять ситуацию давайте представим себе небольшой супермаркет, касса представляет собой аналог процессора, тик - среднее время обслуживания покупателя (скажем, 1 минута), а процессы - это покупатели. В разгар рабочего дня людей в магазине немного, и вы спокойно прошли на свободную кассу, рассчитались и пошли по своим делам. Это хорошо, но как оценить нагрузку на кассу? Для этого нужно взять некий промежуток времени, допустим 10 минут. Если за 10 минут в магазине кроме вас было еще три человека, то средняя загрузка составит 0,4.
А теперь зайдем в магазин вечером, все кассы заняты, и чтобы оплатить покупки придется ждать. Теперь если за 10 минут касса обслужила 10 человек и еще 10 стоят в очереди, то средняя загрузка будет равна 2, хотя касса загружена всего на 100%.
Вернемся к процессору и еще одному моменту, процессам, ожидающим окончания операций ввода-вывода (диск, сеть и т.п.). Во многих источниках указывается, что такие процессы искажают результат load average и мы можем получить высокие значения LA при отсутствии загрузки процессора. Да, это так. Посмотрим на еще одну схему ниже:
Как видим, из 9 тиков было использовано только 6, т.е. процессор загружен всего на 67%, но так как три процесса ждут данные от диска, то load average по-прежнему равен 1.
Если продолжать аналогию с супермаркетом, то похожая ситуация возникает, когда вы уже подошли к кассе и уже собрались выгружать продукты на ленту, но ваша супруга говорит вам, что она забыла купить хлеб, и вы тут стойте, а она сбегает. Собственно, все что вам остается до того, как она принесет хлеб, это стоять рядом с кассой и ждать, пропуская тех, кто находится в очереди позади вас.
Искажают ли такие процессы значение load average? На наш взгляд нет. Следует понимать, что средняя загрузка - это не показатель производительности процессора, не результат бенчмарка, не текущая нагрузка, а отношение числа процессов, которым требуются вычислительные ресурсы системы к имеющимся в наличии ресурсам.
Т.е. если у нас имеется 1 процессор и 500 тиков, но за это время процессорные ресурсы требуются тысяче процессов, то нагрузка у нас явно вдвое превышает имеющиеся ресурсы. И то, что часть процессов ждут жесткий диск и процессор работает вхолостую, не говорит о том, что система находится в простое, наоборот, она не может обработать нагрузку, правда по другой, не зависящей от процессора причине.
Пользователю ведь все равно по какой причине тормозит сайт или приложение, тем более что недостаток дисковых ресурсов обычно выражается подвисании приложения, в то время как при недостатке процессорных оно просто начинает тормозить.
Подведем промежуточный итог. Load average показывает отношение имеющихся запросов на вычислительные ресурсы к количеству этих самых ресурсов (тиков). Для одного процессора (одного процессорного ядра) использование всех имеющихся ресурсов обозначает load average = 1. Причем это будет справедливо и для Core i7 и для Pentium I, хотя производительность у этих двух процессоров разная.
Теперь перейдем к многопроцессорности и многоядерности. При появлении второго процессора или второго ядра у нас появляются дополнительные вычислительные ресурсы, т.е. же самые 500 тиков. Но за эти 500 тиков система уже может обработать уже 1000 запросов, что покажет нам load average = 2.
Значит ли это, что производительность выросла в два раза? Нет! Производительность зависит от того, сколько вычислений способен произвести процессор в течении одного тика. Понятно, что более мощный процессор выполнит за этот промежуток времени больше вычислений, но оба из них сделают одинаковое число тиков (для каждого процессорного ядра). В многопроцессорных (многоядерных) системах часть процессорного времени вместо вычислений занимают задачи межпроцессорного взаимодействия, переключения контекста и т.д. Поэтому появление второго ядра никогда не даст 100% прироста производительности, но всегда позволяет обработать вдвое большее количество запросов.
Это хорошо видно на примере технологии Hyper-threading, которая позволяет сделать из одного физического ядра процессора два виртуальных. Физическая производительность ядра процессора, т.е. количество производимых им вычислений в единицу времени не меняется, но появляется, хоть и виртуальное, но второе ядро, а это еще 500 тиков. Как показывают тесты, прирост производительности от Hyper-threading составляет 15-30%, что еще раз подтверждает старую поговорку, что лучше плохо ехать, чем хорошо стоять. Второе ядро, хоть и виртуальное, позволяет обрабатывать вычислительные запросы тех процессов, которые в одноядерном варианте стояли бы в очереди.
Непонимание этого момента приводит к тому, что load average ошибочно связывают не с доступностью и достаточностью вычислительных ресурсов, а с производительностью процессора, что приводит к неверным выводам.
Например, переводчик довольно неплохой статьи на Хабре делает ошибочный вывод в отношении Hyper-threading:
Хабраюзер esvaf в комментариях интересуется, как интерпретировать значения load average в случае использования процессора с технологией HyperThreading. Однозначного ответа на данный момент я не нашел. В данной статье утверждается, что процессор, который имеет два виртуальных ядра при одном физическом, будет на 10-30% более производительным, чем простой одноядерный. Если принимать такое допущение за истину, считаю, при интерпретации load average стоит брать в расчет только количество физических ядер.
А Википедия вообще написала полную ерунду (что для технических статей там совсем не редкость):
Средняя нагрузка -- это не очень точная характеристика (хотя бы потому, что она определяет усреднённые значения). И если на компьютере есть несколько процессоров, то такой характеристике верить нельзя. Располагая двумя процессорами, можно (теоретически) одновременно выполнять в два раза большее число программ. Это означает, что средняя нагрузка 2.00 (на двухпроцессорном компьютере) будет эквивалентна средней нагрузке 1.00 (на однопроцессорном компьютере). На самом деле это не совсем так. Из-за дополнительной нагрузки, вызванной планированием и некоторыми другими факторами, двухпроцессорный компьютер не обеспечивает удвоения быстродействия по сравнению с однопроцессорным вариантом.
Убедиться, что это не так довольно легко. Если запустить бесконечный цикл командой
1 perl -e 'while(1){}'
то мы обеспечим полную загрузку одного процессорного ядра и load average = 1 (в данный момент смотрим только на первые, минутные показания данного параметра).
Два процесса: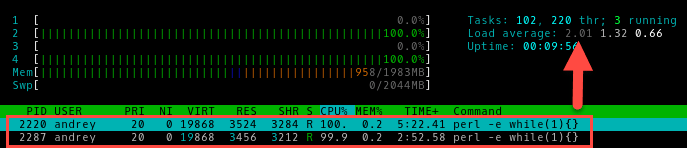
Четыре: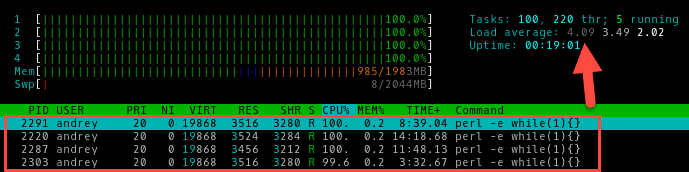
Мы не знаем, сколько именно операций в единицу времени выполняет наш процессор, но нам и не нужно знать это, гораздо важнее понимать, что на текущий момент все вычислительные ресурсы системы задействованы, но недостатка в них нет.
Запустим пятый процесс: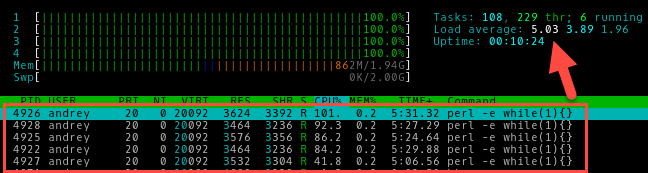
Что изменилось? Загрузка процессора осталась на уровне 100%, это и понятно, выше головы не прыгнешь, но load average вырос до 5, что означает нехватку вычислительных ресурсов примерно на 20%. Таким образом понимание сути значения средней загрузки позволяет администратору однозначно сделать выводы о текущей ситуации, чего не скажешь, глядя просто на индикатор загрузки CPU.
Теперь касательно HyperThreading, виртуализации и т.п. случаев, когда процессор, с которым работает система далеко не соответствует физическому процессору, искусственно создадим данную ситуацию. Для этого запустим на хосте параллельно с виртуальной машиной какой-нибудь ресурсоемкий процесс, например, кодирование видео. Виртуальная машина будет рассчитывать на 4 полных процессорных ядра, а по факту получит в лучшем случае половину их производительности. Проверим?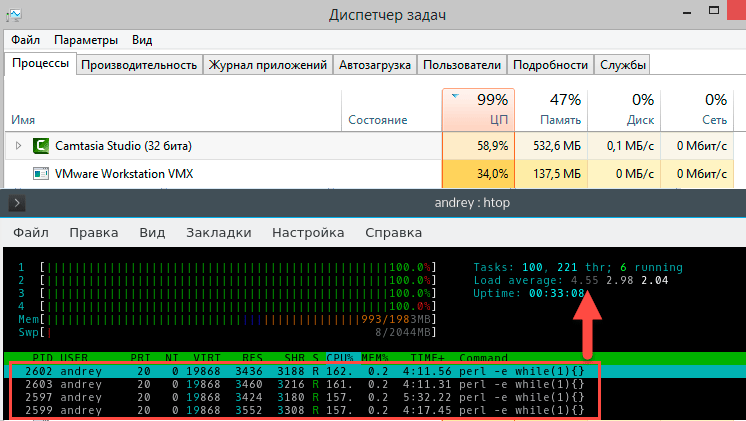
На что следует обратить внимание? В текущих условиях виртуальная машина получает примерно 30-40% загрузки физического процессора. Внутри виртуалки мы видим ожидаемые 100% загрузки процессора, однако если обратить внимание на колонку CPU%, то мы увидим там весьма интересные значения 157-162% загрузки процессора. Почему так происходит? Внутри виртуальной системы тиков CPU хватает всем, но реально гипервизор не выделяет виртуалке процессорного времени. Но это все лирика, что нам показывает load average? Налицо недостаток вычислительных ресурсов - 4,55. Соответствует это реальному положению дел? Да. Нужно ли вносить какие-то коррективы? На наш взгляд - нет.
Теперь уберем стороннюю нагрузку. Гипервизор тут же передаст максимум ресурсов виртуальной машине.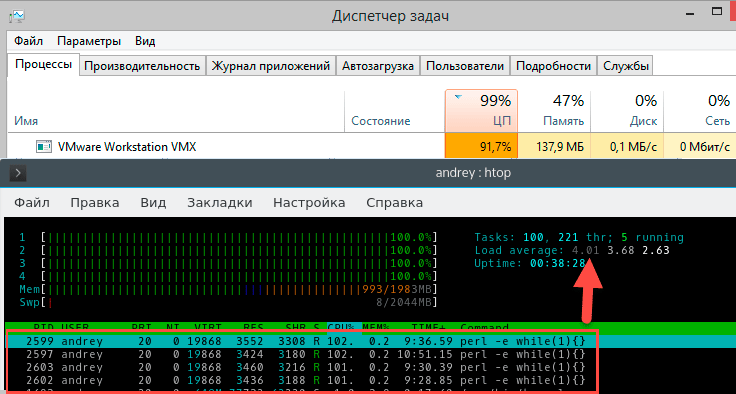
Как видим, вычислительных ресурсов снова стало достаточно и load average опустился до значения 4.
Какие выводы мы можем сделать из этого примера? Что значение load average корректно отражает загрузку системы даже в тех условиях, когда иные показатели не дают корректного представления о происходящих процессах. Так нагрузка на CPU в 157% явно противоречит здравому смыслу, а вот LA = 4,55 вполне реально отражает ситуацию. Поэтому никаких корректив на виртуальные ядра, виртуализацию и т.п. вносить не надо. Load average является относительной величиной и от реальной производительности CPU не зависит в тоже время показывая наличие или дефицит вычислительных ресурсов.
Теперь разберемся с самими цифрами. Мы получаем три значения load average для промежутков в 1, 5 и 15 минут. Как гласит та же Википедия - это средние значения за указанный промежуток времени, что снова неправильно. Для отображения load average используется экспоненциально взвешенная скользящая средняя, подобный тип кривых используется для для сглаживания краткосрочных колебаний и выделения основных тенденций или циклов.
Например, скользящие средние широко применяются в финансовом анализе, для выделения общих тенденций движения курсов валют и акций, позволяя отбросить так называемый "биржевой шум" и понять общие тренды рынка.
То, что подходит финансисту, наверняка подойдет и системному администратору. В чем основное преимущество скользящих средних? В том, что они позволяют выделить основные тенденции, отбросив кратковременные колебания. Это достоинство, а не недостаток, как пытается убедить нас Википедия:
Средняя нагрузка -- это не очень точная характеристика (хотя бы потому, что она определяет усреднённые значения).
Именно усредненные по особому алгоритму значения позволяют нам окинуть ситуацию взглядом вширь и вглубь и разглядеть за деревьями лес. В этом отношении временные значения load average представляют собой не время, за которое посчитали среднее значение, а период времени относительно которого проводится усреднение.
Благодаря автору Хабра ZloyHobbit, который не поленился изучить исходный код Linux, можно точно смоделировать различные значения load average при заданной модели нагрузки. Мы смоделировали ситуацию, когда первые 30 минут единственное ядро CPU было нагружено на 100%, без ждущих в очереди процессов, в последующие полчаса нагрузка была полностью снята.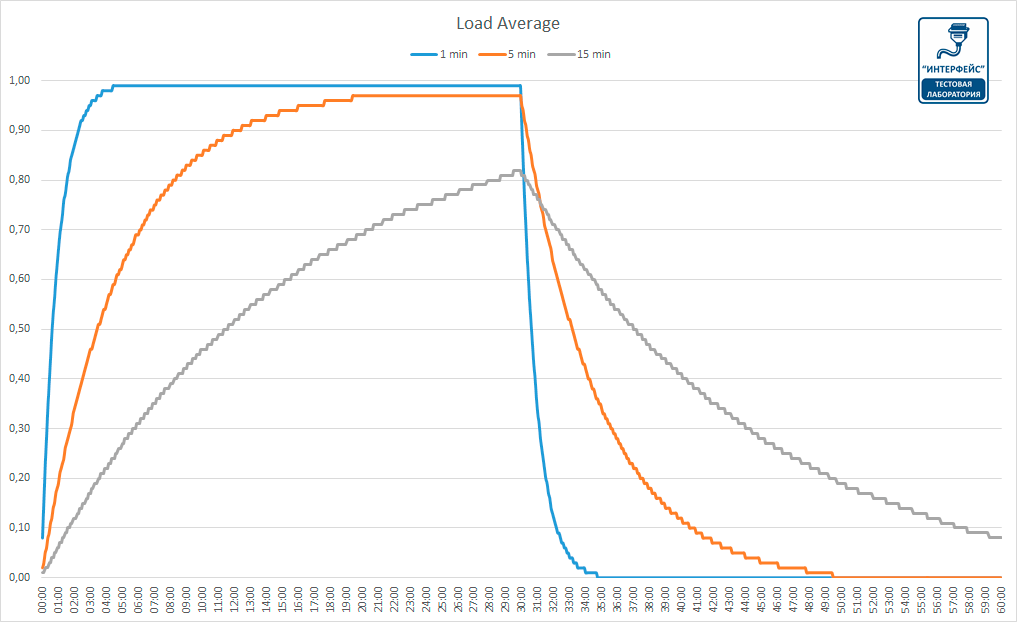
Как видим, разные периоды усреднения дают совершенно различные результаты, так LA 1 (1 min), начинает показывать реальные значения где-то через 4 минуты, LA 5 для отражения текущей нагрузки потребовалось уже 20 минут, а LA 15 за полчаса полной загрузки вышла только на 0,8.
О чем это говорит и как интерпретировать данные значения? Можно сказать, что LA 1 представляет собой недавнее прошлое (несколько минут назад), LA 5 прошлое (полчаса-час) и LA 15 отдаленное прошлое (несколько часов).
Теперь, располагая этим багажом знаний, мы можем правильно интерпретировать простые, на первый взгляд, три числа load average.
Для примера возьмем такое значение:
1load average: 0.99 0.75 0.35
Это говорит о том, что имеет место достаточно кратковременный (около десятка минут) всплеск нагрузки, при этом вычислительных ресурсов пока достаточно.
А вот значение:
1load average: 0.00 0.36 0.59
Говорит о том, что не так давно система испытывала значительные нагрузки в течении довольно продолжительного времени (полчаса-час).
А вот такая картина:
1 load average: 4.55 4.22 4.18
Для четырехядерного процессора означает, что он работает на пределе своих возможностей в течении длительного времени (несколько часов).
Как видим, load average, несмотря всего на три цифры, способна представить системному администратору огромный пласт информации о фактической загрузке системы на протяжении последних нескольких часов.
Теперь самое время дать ответы на вопросы, поставленные нами в начале статьи: "Много это или мало? Хорошо или плохо? " Для одного ядра мы считаем приемлемыми следующие значения:
- LA 1 - может превышать 1.00, свидетельствуя о кратковременной пиковой нагрузке на систему.
- LA 5 - не должен превышать 1.00, в противном случае налицо явный недостаток вычислительных ресурсов.
- LA 15 - максимальное значение 0.7 - 0.8, но в любом случае не выше 1.0, в противном случае вы можете получить в три часа ночи звонок от руководства с вопросом: " А что это с нашим сервером???"
На многоядерной (многопроцессорной) системе значения load average следует откорректировать пропорционально числу ядер. Узнать их количество можно командой
1nproc
или
1cat /proc/cpuinfo | grep "cpu cores"
Так, например, с учетом вышесказанного, для четырехядерной системы LA 15 не должен превышать 3.00, для двухядерной 1.5, а для одноядерной 0.75.
Теперь, понимая, что такое load average и каким образом формируются его значения вы всегда сможете быстро оценить производительность собственной системы и вовремя принять меры если в работе вашего сервера возникнут узкие места.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе
"Архитектура современных компьютерных сетей"
вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов.
На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:
![]()
Или подпишись на наш Телеграм-канал: ![]()